Có một số công cụ mà bạn có thể sử dụng để làm điều này. gImageReader là một trong số đó. Nó miễn phí và hoạt động với cả tệp hình ảnh và tài liệu PDF.
Hãy cùng FUNiX tìm hiểu chi tiết về gImageReader và xem cách bạn có thể sử dụng nó để trích xuất văn bản từ hình ảnh và PDF.
GImageReader là gì?
gImageReader là một ứng dụng cho phép trích xuất văn bản từ hình ảnh và PDF trên Linux. Về cơ bản, nó là giao diện người dùng của công cụ Tesseract OCR (viết tắt của Optical Character Recognition, nghĩa là Nhận dạng ký tự quang học), một công cụ mã nguồn mở được phát triển bởi HP và được coi là một trong những công cụ OCR tốt nhất hiện tại.
gImageReader, giúp trích xuất văn bản từ hình ảnh hoặc tài liệu PDF một cách dễ dàng và khá chính xác với một vài cú nhấp chuột đơn giản. Sau đó, bạn có thể xuất văn bản đã trích xuất thành tệp văn bản hoặc PDF để sử dụng.
Tính năng của gImageReader
gImageReader bao gồm các tính năng sau:
- Nhập tài liệu PDF và hình ảnh từ các nguồn khác nhau (đĩa, thiết bị quét, khay nhớ tạm và ảnh chụp màn hình)
- Xử lý hàng loạt hình ảnh hoặc tài liệu, tức là trích xuất văn bản từ nhiều hình ảnh hoặc tài liệu cùng một lúc
- Nhận dạng các đoạn văn bản dưới dạng văn bản thuần túy hoặc tài liệu hOCR
- Trình kiểm tra chính tả tích hợp
- Tự động phát hiện vùng văn bản
- Chỉnh sửa hình ảnh/tài liệu cơ bản
- Lưu đầu ra dưới dạng tệp văn bản
Cách cài đặt
gImageReader có trên hầu hết các bản phân phối Linux chính. Nhưng trước khi tiến hành cài đặt, bạn cần cài đặt công cụ Tesseract OCR trên hệ thống.
Để thực hiện việc này, hãy mở Software Manager (Trình quản lý phần mềm) trên hệ thống của bạn và tìm kiếm tesseract. Khi nó trả về một danh sách kết quả, hãy cài đặt các gói tesseract-ocr và tesseract-ocr-eng. Bạn cũng có thể sử dụng trình quản lý gói dòng lệnh để cài đặt.
Sau đó, hãy xem hướng dẫn cài đặt trong các phần sau để cài đặt gImageReader trên máy tính.
Nếu bạn đang sử dụng Debian hoặc Ubuntu, hãy mở terminal và chạy các lệnh dưới đây để cài đặt gImageReader:
sudo add-apt-repository ppa:sandromani/gimagereader
sudo apt-get update
sudo apt install gimagereaderTrên Fedora, CentOS hoặc Red Hat Enterprise Linux (RHEL):
sudo dnf install gimagereader-qt Trên Arch Linux hoặc Manjaro:
sudo pacman -S gimagereaderNgười dùng openSUSE có thể cài đặt gImageReader bằng cách sử dụng:
sudo zypper install gimagereaderCách sử dụng
gImageReader dễ sử dụng và hoạt động với tất cả các loại tệp hình ảnh cũng như tài liệu PDF. Dưới đây là hướng dẫn để trích xuất văn bản từ hình ảnh hoặc PDF trên Linux.
Mở menu ứng dụng, tìm kiếm gImageReader và khởi chạy ứng dụng. Nhấn nút Maximize trong cửa sổ gImageReader để mở nó ở chế độ xem toàn màn hình.
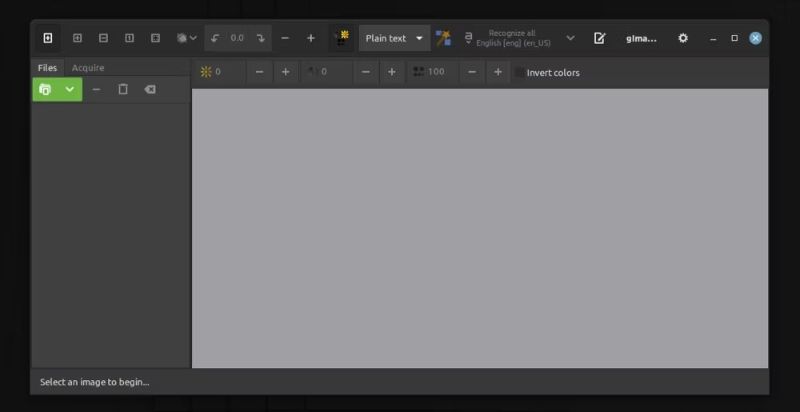
Bây giờ, nhấp vào nút Add images (Thêm hình ảnh) trên ngăn bên trái dưới thanh công cụ và sử dụng trình duyệt tệp để chọn (các) hình ảnh hoặc (các) PDF mà bạn muốn trích xuất văn bản.
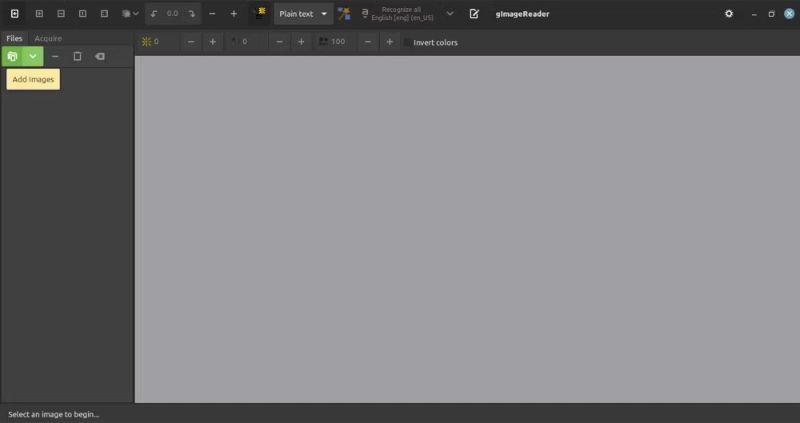
Nhấp vào Ok để nhập (các) hình ảnh hoặc file PDF vào gImageReader. Hoặc, nếu bạn muốn trích xuất văn bản từ những gì hiển thị trên màn hình, hãy nhấp vào menu thả xuống bên cạnh nút Thêm hình ảnh và chọn Take Screenshot (Chụp ảnh chụp màn hình). gImageReader sẽ chụp ảnh nội dung của màn hình.
Khi bạn đã thêm hình ảnh vào gImageReader, hãy nhấp vào nút Toggle output pane (Chuyển đổi ngăn đầu ra – một nút có biểu tượng notepad) để hiển thị ngăn đầu ra. Đây là nơi xuất hiện văn bản bạn trích xuất từ hình ảnh hoặc PDF.
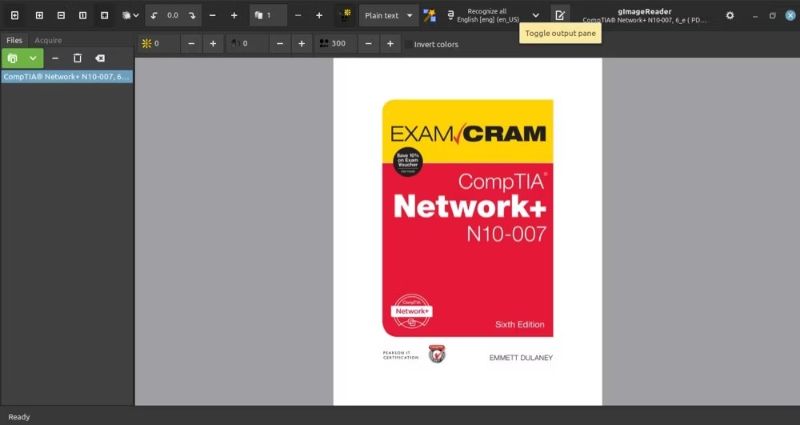
Tùy thuộc vào cách bạn muốn tiếp tục, bây giờ bạn có tùy chọn nhận dạng văn bản trong hình ảnh hoặc PDF tự động hoặc thủ công. Để thực hiện việc này tự động, hãy nhấp vào nút Autodetect layout (Tự động phát hiện bố cục) và nó sẽ đánh dấu tất cả các khối văn bản trong hình ảnh hoặc tài liệu PDF đã chọn.
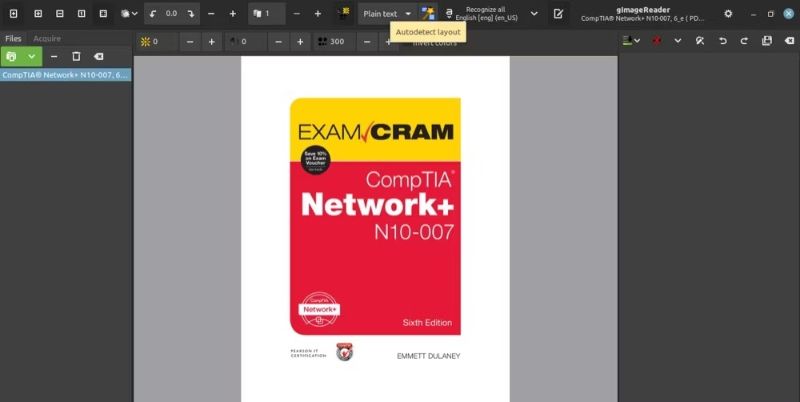
Sau đó, hãy nhấp vào Nhận biết lựa chọn> Trang hiện tại (Recognize selection > Current Page) để bắt đầu quá trình trích xuất văn bản.
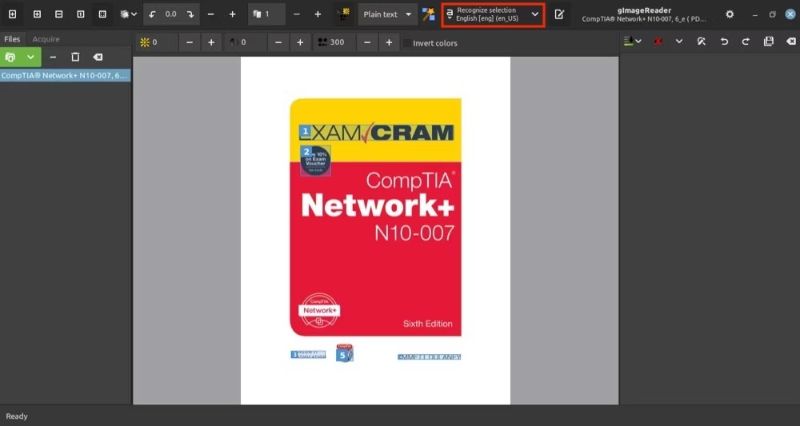
Ngoài ra, để chọn văn bản theo cách thủ công, hãy di chuột qua văn bản muốn trích xuất và sử dụng dấu chéo để vẽ một hộp xung quanh khu vực mà bạn muốn trích xuất văn bản. Sau đó, nhấn nút Recognize selection (Nhận biết lựa chọn) để tiếp tục.

Nếu đó là tài liệu PDF và bạn muốn trích xuất văn bản từ các trang khác nhau, hãy nhấn vào nút Dấu cộng ( + ) để lật trang.
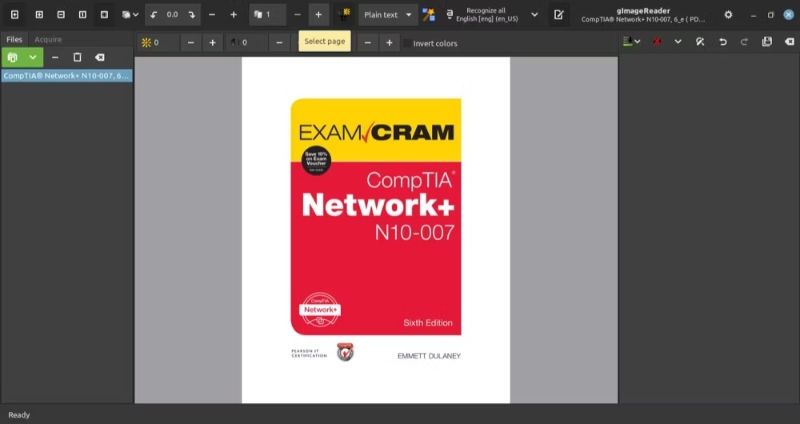
Để quay lại, nhấn nút Trừ ( – ). Và sau đó, chọn văn bản bạn muốn trích xuất và nhấn nút Nhận dạng lựa chọn để trích xuất nó.
Đôi khi gImageReader sẽ trả về văn bản được trích xuất bằng một ngôn ngữ không phải là tiếng Anh. Khi điều này xảy ra, chỉ cần nhấn vào nút thả xuống bên cạnh nút Nhận dạng lựa chọn và chọn một trong các tùy chọn tiếng Anh.
Cuối cùng, để lưu văn bản đã trích xuất, hãy nhấp vào nút Save output (Lưu đầu ra). Thao tác này sẽ hiển thị cửa sổ Lưu. Tại đây, đặt tên cho tệp và nhấn Ok.
Bạn có thể làm gì khác với gImageReader?
Như đã nói, gImageReader cũng cung cấp cho bạn tùy chọn để sửa đổi một số khía cạnh nhất định của hình ảnh hoặc tài liệu đã nhập, như độ sáng, độ tương phản và độ phân giải của chúng. Ngoài ra, bạn cũng có thể đảo ngược màu sắc hoặc xoay hình ảnh hoặc tài liệu nếu cần.
Hầu hết các tùy chọn này có thể hữu ích khi văn bản trong hình ảnh hoặc tài liệu không dễ đọc đối với gImageReader và do đó, ngăn trở công cụ nhận dạng văn bản.
Để truy cập bất kỳ tùy chọn chỉnh sửa nào trong số này, hãy nhấp vào nút Image Controls (Điều khiển Hình ảnh) và nó sẽ hiển thị một thanh công cụ nhỏ bên dưới thanh công cụ chính. Từ đây, hãy chọn các nút thích hợp để thực hiện thao tác chỉnh sửa mong muốn trên hình ảnh hoặc tài liệu.
Trích xuất văn bản trên Linux trở nên dễ dàng với gImageReader
Việc trích xuất văn bản thường yêu cầu một ứng dụng sử dụng công cụ OCR đáng tin cậy và chính xác, cho phép nó xác định văn bản trong hình ảnh hoặc tài liệu một cách hiệu quả.
gImageReader hoàn thành điều này một cách tuyệt vời, nhờ vào công cụ Tesseract OCR mà nó sử dụng. Xét về tính dễ sử dụng, gImageReader chắc chắn là một trong những công cụ trích xuất văn bản tốt nhất hiện có cho Linux.
Ngoài ra, nếu bạn đang tìm kiếm một giải pháp đơn giản hơn, bạn có thể xem xét TextSnatcher, ứng dụng này cũng nhanh và khá dễ sử dụng.
>> XEM THÊM: Cách trích xuất văn bản từ hình ảnh trên Linux với TextSnatcher
Vân Nguyễn
Dịch từ: https://www.makeuseof.com/extract-text-pdfs-images-on-linux-gimagereader/







Bình luận (0
)