Chuyển việc Data Scientist hoặc tích hợp khoa học dữ liệu vào công việc - nghề nghiệp thời thượng của dân kinh tế để bứt phá trong thời kỳ chuyển đổi số.
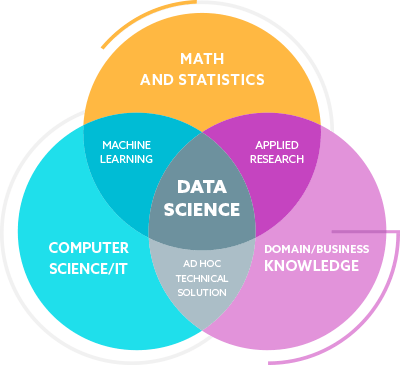
Data Science là thu thập, khai thác và phân tích các giá trị từ khối dữ liệu data khổng lồ theo cấu trúc. Data Science = Advanced Mathematics (Statistics, Linear Algebra, Calculus), Programming (Python, Database, Data Structure and Algorithm) và Kiến thức về lĩnh vực kinh tế xã hội cụ thể.
Chương trình Data Science trang bị các kiến thức cơ bản về data modelling/analysis techniques cũng như life cycle của một dự án Data Science để sinh viên có được hiểu biết cơ bản về Data Science và ứng dụng.
Data Science giúp phân tích, đưa ra các xu hướng, mô hình phát triển và dự báo cho tương lai. Căn cứ vào đó, các ngành hàng, dịch vụ có thể đưa ra đánh giá, quyết định cho việc đầu tư, thu hồi hoặc phát triển các giá trị hữu ích.
1.2 Nhà Khoa học dữ liệu (Data Scientist) làm gì?
Data Scientist là những người tạo ra giá trị từ data, với 2 nhiệm vụ chính là:
Thu thập, xử lý dữ liệu để tìm ra/phát hiện ra những giá trị ẩn chứa trong nó.
Chuyển hóa những giá trị đó thành các giải pháp/hành động, từ đó tạo ra các giá trị và lợi ích thực cho tổ chức/công ty.
1.3 Đối tượng thích hợp làm việc trong lĩnh vực Data Science
Khóa học Data Science phù hợp với tất cả mọi người muốn tìm hiểu và làm việc với dữ liệu, đặc biệt đối với một số đối tượng sau:
Các bạn sinh viên chuyên ngành CNTT/toán tin ứng dụng có kiến thức lập trình cơ bản.
Các bạn sinh viên chuyên ngành kinh tế/sư phạm tự nhiên có kiến thức nền tảng về toán và xác suất thống kê.
Các bạn kỹ sư CNTT muốn chuyển đổi nghề nghiệp
Các bạn chuyên viên làm việc trong các mảng về kinh tế, ngân hàng, fintech có mong muốn làm việc sâu hơn với dữ liệu.
2. Chương trình đào tạo Data Science của xSeries FUNIX
Chương trình Data Science bao gồm đầy đủ các môn học giúp trang bị các kiến thức cơ bản về data modelling/analysis techniques cũng như life cycle của một dự án Data Science để học viên có được hiểu biết cơ bản về Data Science và ứng dụng.
2.1 Mục tiêu (Học viên học xong có năng lực gì?)
Hiểu được các khái niệm cơ bản và phương pháp luận trong khoa học dữ liệu, các bước trong một dự án data science.
Sử dụng thành thạo ngôn ngữ lập trình Python trong việc thống kê dữ liệu, cài đặt các thuật toán học máy và hiển thị hóa dữ liệu (data visualization).
Hiểu được xu hướng, sự phân bố và sự tương quan giữa các đặc tính của dữ liệu và thực hành được về data visualization.
Nắm được kiến thức cơ bản về xác suất thống kê
Biết được các thuật toán cơ bản trong học máy: regression, classification, clustering.
Hiểu được các khái niệm cơ bản trong Deep Learning và sử dụng thuật toán vào các bài toán thực tế.
Sử dụng thành thạo các ứng dụng sau cho các bài toán thu thập, xử lý và phân tích dữ liệu: Excel, Power BI, Python và một số framework đặc thù khác (scikit-learn, pandas, …).
2.2 Yêu cầu đầu vào và đối tượng phù hợp
Đã hoàn thành môn học: Xác suất thống kê.
Có kinh nghiệm lập trình với Python.
Có kiến thức về sử dụng ngôn ngữ SQL.
Trong trường hợp chưa có đầy đủ các kiến thức điều kiện, các bạn cần học thêm các môn học sau trong học phần điều kiện của chương trình Data Science:
Gia nhập các công ty sản xuất phần mềm ở lĩnh vực Data Science/AI của Việt Nam như FPT AI – FPT Software, Tinh Vân, CMC.
Đảm nhiệm vị trí phân tích dữ liệu trong lĩnh vực tài chính, ngân hàng, marketing như Vietcombank, Techcombank, VP Bank, …
Tham gia các vị trí trong dự án phát triển hệ thống AI/Data Science cho các doanh nghiệp có lượng data rất lớn và dồi dào như Viettel, VNPT AI, Lazada …
Làm việc như một data scientist/data analyst tại các công ty cần thu thập, lưu trữ và xử lý dữ liệu, công ty khởi nghiệp như ELSA, Cinnamon AI, Trusting Social, …
2.4 Cấu trúc chương trình học khoá học Data Science
Môn học này giới thiệu cho người học các khái niệm cơ bản trong khoa học dữ liệu (Data Science) bao gồm data science là gì, các chủ đề và thuật toán trong Data Science và ứng dụng trong thực tế. Ngoài ra môn học giới thiệu phương pháp luận sử dụng trong khoa học dữ liệu, vòng đời dự án Data Science. Học viên cũng được dạy về lập trình Python cơ bản và ôn tập lại về xác suất thống kê.
Biết cách lập trình Python cơ bản, các cấu trúc dữ liệu trong Python, làm việc với Pandas và Numpy
Nắm được các kiến thức kỹ năng cần thiết cho Data Science trong xác suất thông kê
Hiểu được các khái niệm cơ bản, các chủ đề, các ứng dụng của Data Science
Hiểu được phương pháp luận sử dụng trong data science, các bước để giải quyết các vấn đề data science từ nêu được bài toán, thu thập và phân tích dữ liệu, xây dựng thuật toán và hiểu được phản hồi sau khi thuật toán được cài đặt và sử dụng
Rất nhiều dữ liệu trên thế giới hiện nay được lưu trên cơ sở dữ liệu, kiến thức về cơ sở dữ liệu và ngôn ngữ SQL rất cần thiết để trở thành nhà khoa học dữ liệu. Môn học cung cấp kiến thức về các khái niệm cơ sở dữ liệu quan hệ, thực hành các câu lệnh query sử dụng ngôn ngữ SQL và Python. Học viên học làm việc sâu với Pandas, Numpy để khám phá nhiều dạng dữ liệu, làm sạch dữ liệu, xử lý dữ liệu bị thiếu. Môn học dạy cách biểu diễn dữ liệu để hiểu sâu hơn về dữ liệu, giúp đưa ra các quyết định hiệu quả.
Viết được các câu lệnh SQL cơ bản: CREATE, DROP, SELECT, INSERT, UPDATE, DELETE
Biết vận dụng các câu lệnh truy vấn nâng cao như filter, sort, group
Sử dụng Python để truy cập vào cơ sở dữ liệu
Biết import và export data
Nắm được cách tiền xử lý dữ liệu, xử lý dữ liệu bị thiếu, chuẩn hóa dữ liệu
Thực hiện được thống kê dữ liệu, tìm độ tương quan trong dữ liệu
Biết cách biểu diễn dữ liệu theo dạng biểu đồ sử dụng các thư viện Matplotlib
Học được cách biểu diễn dữ liệu dạng nâng cao qua thư viện Seaborn và Folium
Học viên được dạy mục đích của học máy và các ứng dụng trong thực tế. Môn học trang bị các thuật toán trong học máy: regression, classification, clustering, recommender system.
Nắm được tổng quan về các topic trong machine learning: supervised learning, unsupervised learning
Hiểu và thực hành các thuật toán về Regression
Hiểu và thực hành các thuật toán về Classification
Hiểu và thực hành các thuật toán về Clustering
Hiểu về Recommender Systems
Thực hành cách thuật toán vào bài toán thực tế
Biết cách biểu diễn dữ liệu theo dạng biểu đồ sử dụng các thư viện Matplotlib
(Các bạn click vào link để đọc thêm các thông tin chi tiết về môn học).
Mục tiêu của khóa học này là cung cấp cho người học sự hiểu biết cơ bản về các neural network hiện đại và các ứng dụng của chúng trong thị giác máy tính và nghiên cứu ngôn ngữ tự nhiên. Sau khi đã tìm hiểu các mô hình tuyến tính, gradient descent và đi sâu hơn vào các phương pháp tối ưu, điển hình cho việc huấn luyện deep neural networks, chúng ta sẽ tiếp tục với các lớp phổ biến nhất của neural network là lớp fully connected (phân loại), lớp convolution (thị giác máy tính) và các lớp recurrent (xử lý ngôn ngữ tự nhiên). Sau đó, bạn sẽ sử dụng các lớp này để xây dựng các mô hình DNN đầy đủ sử dụng các framework Tensorflow và Keras. Trong các dự án trong khóa học, bạn sẽ giải quyết vấn đề nhận diện khuôn mặt đeo khẩu trang và phân loại văn bản độc hại bằng cách sử dụng Keras.
#
Mục tiêu
1
Nắm được khái niệm cơ bản, ứng dụng và vai trò của Deep Learning hiện nay trong thị giác máy tính và xử lý ngôn ngữ tự nhiên.
2
Nắm được các ứng dụng của DL vào trong thị giác máy tính thông qua kiến trúc mạng CNN (CNN, VGG, Resnet, Inception, MobileNet, EfficientNet): Bài toán phân loại hình ảnh, nhận diện vật thể, phân vùng theo nhóm, nhận diện khuôn mặt.
3
Nắm được ứng dụng của DL vào trong xử lý ngôn ngữ tự nhiên thông qua các kiến trúc mạng về RNN (RNN, LSTM, GRU, Attention và Transformation): Nhận diện cảm xúc thông qua văn bản, dịch máy, xây dựng và sử dụng Word Embedding.
4
Sử dụng được Tensorflow để xây dựng một dự án hoàn chỉnh về Machine Learning và Deep Learning.
5
Có năng lực về chuẩn hóa dữ liệu, xây dựng và đánh giá, phân tích lỗi, cải thiện và tối ưu model trong các dự án ML/DL.
Power BI đang nhanh chóng trở thành nền tảng BI (kinh doanh thông minh) mạnh mẽ nhất trên thế giới và là một trong những công cụ rất hữu ích cho cả các chuyên gia dữ liệu cũng như những người mới bắt đầu tìm hiểu về phân tích dữ liệu. Với Power BI, bạn có thể kết nối với hàng trăm nguồn dữ liệu, xây dựng các mô hình phức tạp bằng các công cụ đơn giản và trực quan, đồng thời thiết kế các bảng báo cáo và điều khiển tương tác tuyệt đẹp.
Trong khóa học này, bạn sẽ đóng vai trò là Nhà phân tích kinh doanh của Adventure Work Cycles, một công ty sản xuất toàn cầu. Nhiệm vụ của bạn sẽ là thiết kế và cung cấp một giải pháp kinh doanh thông minh đầu cuối, chất lượng và chuyên nghiệp thông qua Power BI với đầu vào là các tệp dữ liệu thô.
Chúng ta sẽ được hướng dẫn chi tiết cách sử dụng Power BI Desktop để thực thi nhiệm vụ trên. Bên cạnh đó, môn học sẽ cung cấp cho bạn các giải thích rõ ràng cũng như các kỹ thuật chuyên nghiệp hữu ích trong từng quá trình thực hiện. Chúng ta sẽ đi theo một tiến trình ổn định, có hệ thống để hoàn thành được một dự án hoàn chỉnh về Power BI.
#
Mục tiêu
1
Hiểu về lợi ích của Business Intelligence đối với doanh nghiệp.
2
Cài đặt và làm quen với giao diện của Power BI Desktop.
3
Xử lý, chuyển đổi và tích hợp được dữ liệu thô vào Power BI.
4
Xây dựng mô hình dữ liệu quan hệ với các bảng dữ liệu và quan hệ dữ liệu.
5
Sử dụng DAX để tính toán, trích xuất và phân tích dữ liệu.
6
Xây dựng được các báo cáo Power BI đẹp mắt, có thể tương tác với người dùng.
7
Thiết kế, xây dựng và triển khai được một quy trình BI hoàn chỉnh trên Power BI từ dữ liệu thô với các báo cáo và dashboard chất lượng.
Hoàn thành môn học, học viên sẽ biết cách kết hợp các kiến thức về dữ liệu để tạo ra một đề xuất giải pháp công nghệ và xây dựng được tài liệu nghiệp vụ liên quan đến giải pháp đó.
Học viên có thể chọn 1 trong 2 option sau:
Option 1: Làm đồ án tốt nghiệp
Đối với các học viên theo học chương trình biên soạn, học viên sẽ được hướng dẫn chọn làm đề tài/khóa luận với các mentor hướng dẫn trực tiếp.
Option 2: Đi thực tập doanh nghiệp
Đối với các bạn học viên có nguyện vọng thực tập tại các doanh nghiệp, FUNiX sẽ hỗ trợ kết nối các bạn với các doanh nghiệp để chuẩn bị CV và phỏng vấn vào thực tập. Nếu được doanh
Phương án thực hành
Chương trình có đề bài thực hành giúp học viên rèn luyện khả năng lập trình bám theo các bài lý thuyết đã được dạy.
#
Môn học
Định hướng Course Project
11
Giới thiệu về Khoa học Dữ liệu
Assignment 1: Phương pháp luận Khoa học dữ liệu
Chủ đề: Bạn có thể áp dụng những kiến thức đã học để giải quyết một trong các vấn đề sau với vai trò của một khách hàng cũng như một nhà khoa học dữ liệu. Đầu tiên, bạn cần chọn một chủ đề mà bạn quan tâm. Sau đó, hãy thực hiện theo các giai đoạn (stages) của Phương pháp luận Khoa học Dữ liệu và mô tả những việc cần làm để giải quyết vấn đề đó.
Mục tiêu:Bài tập cung cấp cho học viên một kĩ năng thực tế để làm việc với phương pháp luận khoa học dữ liệu. Học viên sẽ áp dụng các quy tắc phương pháp luận để tìm ra hướng giải quyết cho vấn đề của bạn..
Assignment 2: Tính toán và phân tích điểm thi (Test Grade Calculator)
Chủ đề:Trong bài tập lớn này, bạn cần viết một chương trình để tính toán điểm thi cho nhiều lớp với sĩ số hàng nghìn học sinh. Mục đích của chương trình giúp giảm thời gian chấm điểm.
Mục tiêu:Bạn sẽ học cách viết một chương trình Python tập trung vào lập trình cơ bản, sử dụng list, function và xử lý với chuỗi. Hơn nữa, bạn sẽ biết cách truy cập file để đọc dữ liệu và ghi kết quả thống kê được.
Yêu cầu:Bài tập này cung cấp cho học viên một nguồn dữ liệu thực tế. Các bạn sẽ thực hành sử dụng các hàm khác nhau trong Python để giải quyết một bài toán cụ thể.
22
Phân tích dữ liệu với Python
Assignment 1: Truy xuất và phân tích dữ liệu bóng đá châu Âu
Chủ đề:Bạn nhận được Cơ sở dữ liệu bóng đá châu Âu có hơn 25.000 trận đấu và hơn 10.000 cầu thủ cho các mùa bóng đá chuyên nghiệp châu Âu từ 2008 đến 2016. Mục tiêu là bạn xem qua cơ sở dữ liệu này và thực hiện phân tích, bao gồm một số bước khám phá dữ liệu, thống kê cơ bản và sau đó trực quan hoá kết quả. Để hoàn thành tất cả các bước, bạn cần truy vấn dữ liệu trong cơ sở dữ liệu bằng cách sử dụng câu lệnh SQL. Thông qua dự án này, ban có thể thực hành viết lệnh SQL để lấy dữ liệu về và trích xuất nó.
Mục tiêu: Đề tài này cung cấp một cơ sở dữ liệu thực tế và bạn sẽ thực hành tất cả các câu lệnh SQL trong bài học.
Yêu cầu:
Kết nối với cơ sở dữ liệu sqlite bằng lập trình Python
Viết câu lệnh SQL: Select, group by, order by
Viết câu lệnh SQL nâng cao: Union
Viết truy vấn con
Assignment 2: Phân tích dữ liệu Covid-19
Chủ đề:Coronavirus là một họ virus được đặt theo tên của chủng Virus coronavirus mới, còn được gọi là SARS-CoV-2, là một loại virus lây truyền qua đường hô hấp lần đầu tiên được phát hiện ở Vũ Hán, Trung Quốc. Vào ngày 2/11/2020, Tổ chức Y tế Thế giới đã chỉ định tên COVID-19 cho bệnh do coronavirus mới gây ra. Dự án này nhằm mục đích tìm hiểu COVID-19 thông qua phân tích dữ liệu và dự báo.
Mục tiêu: Bạn sẽ học cách viết chương trình Python để tải dữ liệu từ file bằng cách sử dụng gói DataFrame trong Pandas và sử dụng Thống kê mô tả để hiểu dữ liệu của bạn. Ngoài ra, bạn sẽ thực hành xử lý các giá trị bị thiếu và chuyển đổi lại một số trường trước khi phân tích đặc trưng riêng lẻ. Trong bước phân tích, bạn sẽ bắt đầu bằng cách nêu ra một số câu hỏi, sau đó khám phá dữ liệu và áp dụng các kỹ năng trực quan hóa dữ liệu bằng Matplotlib, Seaborn, Folium, Bokeh, v.v. để minh họa kết quả. Cuối cùng bạn sẽ chọn các đặc trưng phù hợp nhất giúp bạn dự đoán thời gian di chuyển.
33
Học máy cho Khoa học Dữ liệu
Assignment 1: Dự đoán số người trúng tuyển American College
Chủ đề:Dự án này liên quan đến tập dữ liệu College, trong tệp College.csv thuộc thư mục dữ liệu. Nó chứa một số biến cho 777 trường đại học và cao đẳng khác nhau ở Mỹ.
Mục tiêu: Sau đây là một số câu hỏi mà bạn sẽ gặp phải trong quá trình học:
Làm thế nào để chúng ta áp dụng thuật toán hồi quy Học máy để giải quyết một bài toán thực tế?
Làm thế nào chúng ta có thể thử nghiệm lựa chọn thuộc tính?
Trực quan hóa dữ liệu có thực sự quan trọng trong việc xây dựng một mô hình Học máy?
Sẽ không có một câu trả lời đúng duy nhất cho mỗi câu hỏi trên. Khi thực hiện dự án này, hãy làm việc với các mentors, tiếp thu các ý kiến nhận xét, đánh giá, từ đó phát triển câu trả lời cho những câu hỏi này.
Yêu cầu:Chúng ta sẽ phải phân tích dữ liệu, thực hiện các bước chuyển đổi và tiêu chuẩn hóa cần thiết, áp dụng thuật toán học máy, huấn luyện mô hình, kiểm tra hiệu suất của mô hình được huấn luyện và lặp lại cho đến khi tìm thấy hiệu suất cao nhất cho loại dữ liệu của mình.
Assignment 2: Dự đoán khả năng mắc bệnh tiểu đường loại 2 tại Arizona
Chủ đề:Pima là một nhóm người Mỹ bản địa sống ở Arizona. Nhờ yếu tố di truyền mà nhóm người này có thể tồn tại bình thường với chế độ ăn ít carbohydrate trong nhiều năm. Trong những năm gần đây, sự thay đổi đột ngột từ cây nông nghiệp truyền thống sang thực phẩm chế biến sẵn, cùng với việc giảm các hoạt động thể chất, đã khiến tỷ lệ mắc bệnh tiểu đường loại 2 tăng cao. Và vì lý do này, họ thành đối tượng của nhiều cuộc nghiên cứu. Loại dữ liệu và bài toán là một phân loại nhị phân có giám sát. Cho một số yếu tố, tất cả đều có các đặc điểm (đặc tính) nhất định, chúng tôi muốn xây dựng một mô hình học máy để xác định những người bị ảnh hưởng bởi bệnh tiểu đường loại 2.
Mục tiêu: Sau đây là một số câu hỏi mà bạn sẽ gặp phải trong quá trình học tập:
Quy trình làm việc của một dự án học máy (machine learning workflow) là gì?
Chúng ta có nên làm sạch dữ liệu và trực quan hóa nó trước khi sử dụng nó?
Làm thế nào chúng ta có thể áp dụng chuyển đổi/chuẩn hóa và phân tách dữ liệu?
Làm thế nào để chúng ta áp dụng một thuật toán học máy với các tham số phù hợp nhất?
Các phương pháp kết hợp có giúp chúng ta cải thiện độ chính xác của mô hình/F1-score không?
Sẽ không có một câu trả lời đúng duy nhất cho mỗi câu hỏi trên. Khi thực hiện dự án này, hãy làm việc với các mentors, tiếp thu các ý kiến nhận xét, đánh giá, từ đó phát triển câu trả lời cho những câu hỏi này.
Yêu cầu:Chúng ta cố gắng thực hành tất cả các thuật toán phân loại đã học trong khóa học này: KNN, Hồi quy logistic, Cây quyết định, SVM và các phương pháp kết hợp.
44.1
Học máy: Kỹ thuật học sâu
Assignment 1: Phân loại gương mặt đeo khẩu trang
Chủ đề:Trong bối cảnh hiện nay, khi mà dịch bệnh Covid-19 vẫn còn là một vấn đề không của riêng cá nhân nào thì nhận diện gương mặt một lần nữa thể hiện tầm quan trọng và sự hữu ích của công nghệ này đối với việc ngăn ngừa sự lây lan của dịch bệnh. Bằng cách tự kết hợp một mô hình máy học nhận diện gương mặt và một mô hình phân loại thông qua các nguồn dữ liệu trên mạng, chúng ta sẽ phân loại xem một người trong bức ảnh hoặc camera có đang đeo khẩu trang hay không. Việc phát hiện sớm một người nào đó không đeo khẩu trang góp phần không nhỏ trong việc đẩy lùi và ngăn chặn dịch bệnh lây lan trong cộng đồng, qua đó cải thiện cuộc sống xã hội hiện nay.
Yêu cầu:
Tải các nguồn dữ liệu từ trên mạng và gộp lại thành một tập dữ liệu duy nhất.
Xử lý các dữ liệu hình ảnh.
Mã hóa nhãn của dữ liệu.
Chia tập dữ liệu thành các tập huấn luyện và kiểm định.
Xây dựng mô hình học sâu gồm nhiều lớp khác nhau.
Huấn luyện mô hình.
Sử dụng các mô hình nhận diện gương mặt để trích xuất gương mặt và sau đó phân loại gương mặt.
Chạy mô hình và đánh giá dự đoán trên tập test.
Cải tiến, bổ sung và thay đổi các bước từ 2-8 để có một mô hình có ROC-AUC cao hơn.
Assignment 2: Phân loại bình luận độc hại
Chủ đề:Chúng ta sẽ phát triển các mô hình xác định và gắn cờ các câu hỏi không thành thật bằng cách Deep Learning. Với sự giúp đỡ của bạn, họ có thể phát triển các phương pháp có thể mở rộng hơn để phát hiện nội dung độc hại và gây hiểu lầm.
Mục tiêu:
Dự án này sẽ giúp bạn giải quyết vấn đề NLP bằng RNN từ đầu.
Hơn nữa, nó sẽ giúp mở rộng kiến thức của bạn với ma trận word embedding.
Yêu cầu:
Áp dụng học tập sâu và xử lý ngôn ngữ tự nhiên vào các bài toán thực tế.
Áp dụng một quy trình làm việc deep learning vào thực tiễn: tiền xử lý dữ liệu, mô hình hóa dữ liệu, đánh giá mô hình và tinh chỉnh mô hình.
5
Đồ án cuối khóa – Khoa học Dữ liệu
Mô tả Program Project:
Chủ đề: Bài toán thực tế như sau: Đua ngựa là một môn thể thao lâu đời, vời hình thức thi đua khác nhau ở các quốc gia. Một cuộc đua cần xác định 2 hay nhiều chú ngựa là nhanh nhất trên một đường đua nhất định. Một quốc gia nhất định có dữ liệu từ 21.000 cuộc đua trên web.
Mục tiêu: Học viên được yêu cầu tìm kiếm thông tin từ những dữ liệu này và xây dựng một mô hình dự đoán ba chú ngựa nhanh nhất ứng dụng kỹ thuật phân tích dữ liệu và machine learning.
Học viên tự phát triển tiếp ý tưởng dựa trên dữ liệu đang có.
3. Đội ngũ xây dựng khoá học
Khóa học được xây dựng và thẩm định bởi các chuyên gia hàng đầu về giảng dạy và làm việc trong lĩnh vực Data Science tại Việt Nam, bao gồm:
3.1 Đội ngũ xây dựng chương trình:
Trưởng nhóm VŨ THƯƠNG HUYỀN Data Scientist tại FPT Software – Thạc sĩ ngành Công nghệ phần mềm, ĐHCN, ĐHQG HNTS. TRẦN HỒNG VIỆT Tiến sỹ Khoa học máy tính, Bảo vệ luận án Tiến sỹ về AI tại ĐHCN, ĐHQG HNNGUYỄN HẢI NAM Trưởng nhóm R&D tại công ty Asilla Jp. Thạc sĩ ngành Khoa học Máy tính, Đại học Cassino, Itally.
3.2 Đội ngũ đánh giá và thẩm định chương trình:
PGS. TS. TỪ MINH PHƯƠNG Trưởng khoa CNTT, Học viện CNBCVT
TS. NGUYỄN VĂN VINH Chuyên gia về Trí Tuệ Nhân Tạo, Giảng viên ĐHCN, ĐHQG HN
TS. ĐẶNG HOÀNG VŨ Tiến sỹ Toán Đại học Cambridge, Anh Giám đốc Khoa học FPTTS. TRẦN THẾ TRUNG Viện trưởng Viện CNTT, Đại học FPT
ĐĂNG KÝ NHẬN TƯ VẤN
Cơ hội nghề nghiệp
Sau khi hoàn thành chương trình, học viên sẽ có cơ hội:
● Gia nhập các công việc liên quan đến Data Science tại các công ty công nghệ của Việt Nam như FPT Software, FPT AI, các start-up công nghệ AI, …
● Đảm nhiệm vị trí phân tích dữ liệu (Data Analyst) trong lĩnh vực tài chính, ngân hàng, marketing….
● Tham gia các vị trí trong dự án phát triển hệ thống AI cho các doanh nghiệp lớn.
● Học viên có thể làm vị trí Kỹ sư dữ liệu tại các công ty cần thu thập, lưu trữ và xử lý dữ liệu.
Tầng 0, tòa nhà FPT, 17 Duy Tân, phường Cầu Giấy, Hà Nội
info@funix.edu.vn
0782313602 (Zalo, Viber)
Cơ quan chủ quản: Công ty Cổ phần Giáo dục Trực tuyến FUNiX
MST: 0108171240 do Sở kế hoạch và Đầu tư thành phố Hà Nội cấp ngày 27 tháng 02 năm 2018
Trụ sở chính: Tầng 0, tòa nhà FPT, 17 Duy Tân, phường Cầu Giấy, Hà Nội.
– Văn phòng Hà Nội: Tầng 4, Tòa nhà 25T2, đường Nguyễn Thị Thập, phường Yên Hòa, Hà Nội.
– Văn phòng TP.HCM: Lầu 3A, tòa nhà 51-53 Võ Văn Tần, Phường Xuân Hòa, Thành phố Hồ Chí Minh, Việt Nam
Hotline: 078 231 3602 – Email: info@funix.edu.vn
yêu cầu gọi lại
Yêu cầu FUNiX gọi lại để hỗ trợ thông tin, chương trình học, chỉ tiêu - điều kiện tuyển sinh - học phí,... hoàn toàn FREE