Hướng dẫn đầy đủ về cách sử dụng LightGBM dành cho người mới
- Orange3 - Công cụ lập trình trực quan kéo thả dễ dàng
- AI Kubeflow Pipelines - Nền tảng công nghệ ứng dụng trí tuệ nhân tạo độc đáo
- Khám phá sự khác biệt giữa AutoKeras và AutoML
- Tầm quan trọng của đường ống dữ liệu AI trong học máy
- Tìm hiểu về vai trò của Học máy trong dự đoán địa điểm khảo cổ
Trong lĩnh vực học máy (machine learning), các thuật toán học sâu và các mô hình dựa trên cây quyết định đã trở thành những công cụ quan trọng giúp giải quyết các vấn đề phức tạp. Một trong những thuật toán học máy phổ biến và mạnh mẽ nhất trong số đó là LightGBM (Light Gradient Boosting Machine). Được phát triển bởi Microsoft, LightGBM là một phương pháp boosting dùng cây quyết định (decision tree) và được tối ưu hóa để xử lý dữ liệu lớn, đồng thời cải thiện hiệu suất mô hình. Trong bài viết này, chúng ta sẽ tìm hiểu về LightGBM, cách cài đặt và sử dụng nó, cũng như các ứng dụng và ưu điểm của thuật toán này.
1. LightGBM là gì?
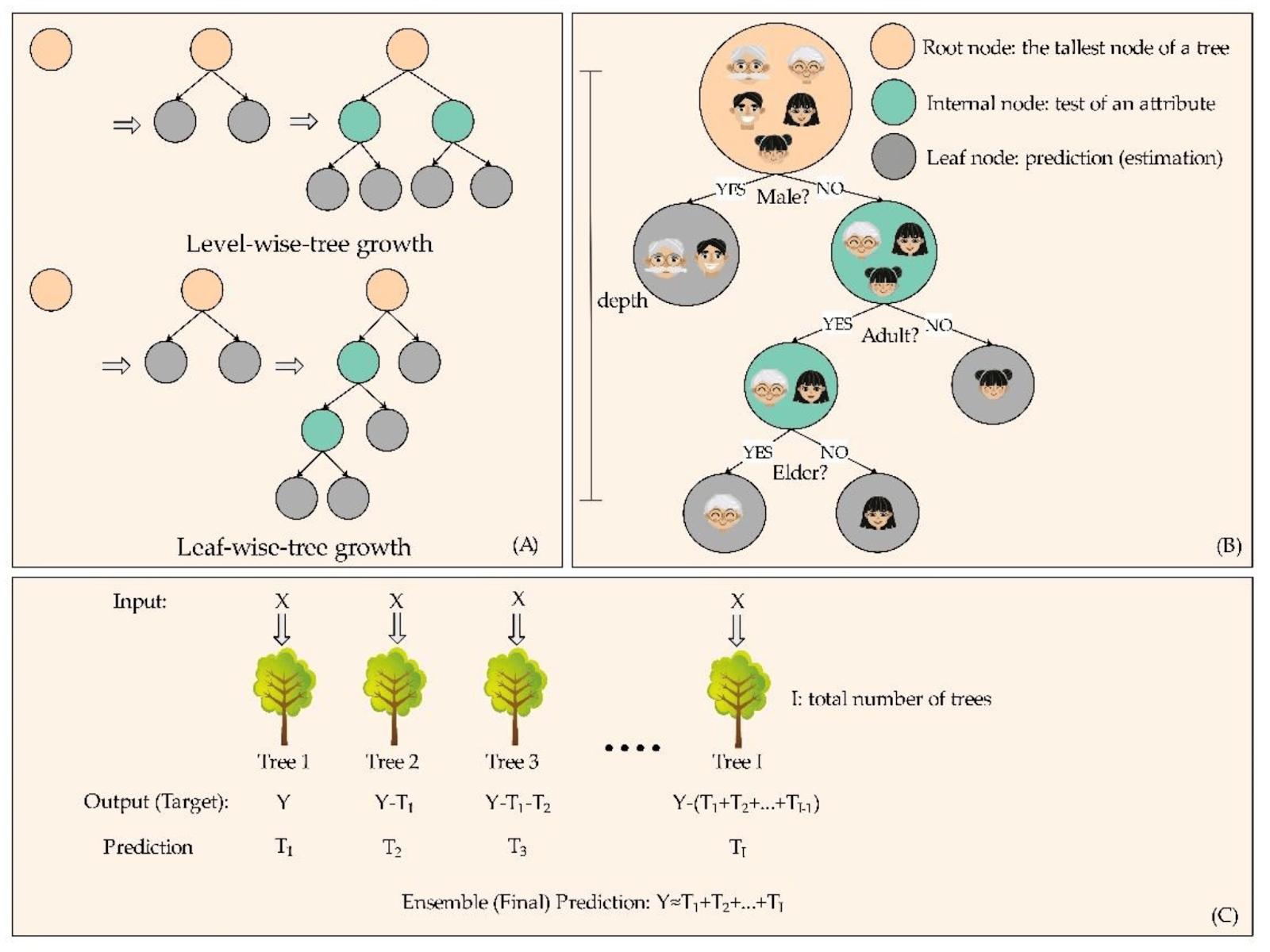
LightGBM (Light Gradient Boosting Machine) là một thư viện học máy hiệu suất cao và được thiết kế để xây dựng các mô hình cây quyết định dựa trên phương pháp boosting. Nó là một phiên bản cải tiến của thuật toán Gradient Boosting, giúp tối ưu hóa tốc độ huấn luyện và giảm thiểu bộ nhớ cần thiết, đặc biệt là khi làm việc với dữ liệu lớn.
Khác với các thuật toán boosting truyền thống, LightGBM sử dụng một cách tiếp cận có tên là Gradient-based One-Side Sampling (GOSS) và Exclusive Feature Bundling (EFB) để tăng tốc quá trình huấn luyện và giảm độ phức tạp tính toán. LightGBM có thể xử lý dữ liệu phân loại và hồi quy, đồng thời hỗ trợ nhiều loại mô hình học máy.
2. Các đặc điểm nổi bật của LightGBM
LightGBM có một số tính năng nổi bật giúp nó trở thành một lựa chọn phổ biến trong học máy:
2.1. Hiệu suất cao
LightGBM được thiết kế để đạt được hiệu suất tốt trên các bộ dữ liệu lớn. Nhờ vào các phương pháp tối ưu hóa hiệu quả như GOSS và EFB, LightGBM có thể huấn luyện các mô hình nhanh chóng mà không cần phải sử dụng quá nhiều bộ nhớ, giúp giảm thiểu chi phí tính toán.
2.2. Hỗ trợ dữ liệu lớn
Một trong những ưu điểm lớn nhất của LightGBM là khả năng xử lý bộ dữ liệu cực lớn. Với phương pháp phân chia dữ liệu đặc biệt, LightGBM có thể làm việc hiệu quả ngay cả khi số lượng mẫu và số lượng đặc trưng rất lớn.
2.3. Hỗ trợ phân loại và hồi quy
LightGBM có thể được sử dụng cho các bài toán phân loại và hồi quy, chẳng hạn như phân loại văn bản, dự báo giá trị chứng khoán, hoặc dự đoán kết quả của các thí nghiệm.
2.4. Tính toán song song và phân tán
LightGBM hỗ trợ tính toán song song và phân tán, điều này giúp tăng tốc quá trình huấn luyện mô hình khi làm việc với các bộ dữ liệu lớn và phức tạp.
2.5. Tính linh hoạt trong việc điều chỉnh tham số
LightGBM cung cấp nhiều tham số có thể điều chỉnh để tối ưu hóa mô hình, từ việc điều chỉnh số lượng cây quyết định đến việc điều chỉnh tốc độ học (learning rate). Điều này giúp người dùng có thể tối ưu hóa mô hình cho từng loại bài toán cụ thể.
3. Cài đặt LightGBM

Trước khi bắt đầu sử dụng LightGBM, bạn cần cài đặt thư viện này. LightGBM có thể được cài đặt thông qua pip hoặc conda.
3.1. Cài đặt qua pip
Nếu bạn sử dụng pip, bạn có thể cài đặt LightGBM bằng cách chạy lệnh sau trong terminal hoặc command prompt:
bash
Sao chép
pip install lightgbm
3.2. Cài đặt qua conda
Nếu bạn sử dụng conda, bạn có thể cài đặt LightGBM bằng lệnh sau:
bash
Sao chép
conda install -c conda-forge lightgbm
Sau khi cài đặt xong, bạn có thể kiểm tra xem LightGBM đã được cài đặt thành công hay chưa bằng cách chạy dòng lệnh Python sau:
python
Sao chép
import lightgbm as lgb
print(lgb.__version__)
>>>Xem thêm:Hướng dẫn cách lọc đường dẫn và kiểm tra index hàng loạt bằng Screaming Frog SEO Spider
4. Cách sử dụng LightGBM
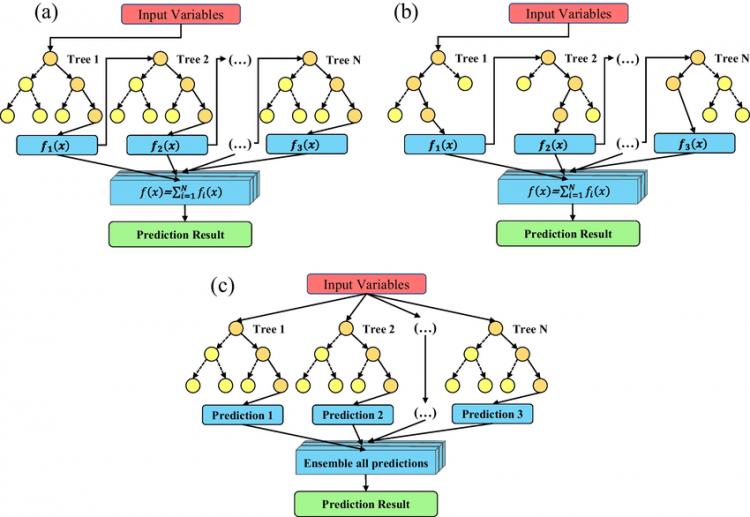
Dưới đây là các bước cơ bản để sử dụng LightGBM trong các bài toán học máy.
4.1. Chuẩn bị dữ liệu
Trước khi sử dụng LightGBM, bạn cần chuẩn bị dữ liệu. LightGBM hỗ trợ đầu vào là dữ liệu dạng ma trận NumPy, pandas DataFrame, hoặc dữ liệu có cấu trúc tương tự. Trong ví dụ dưới đây, chúng ta sử dụng một tập dữ liệu phân loại từ thư viện sklearn.
python
import lightgbm as lgb
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Tải dữ liệu mẫu
data = load_breast_cancer()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = pd.Series(data.target)
# Chia dữ liệu thành tập huấn luyện và kiểm tra
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
4.2. Tạo Dataset cho LightGBM
Trước khi huấn luyện mô hình, bạn cần tạo một đối tượng Dataset từ dữ liệu. LightGBM yêu cầu dữ liệu phải ở định dạng đặc biệt để có thể tối ưu hóa quá trình huấn luyện.
python
Sao chép
# Tạo dữ liệu LightGBM từ DataFrame
train_data = lgb.Dataset(X_train, label=y_train)
test_data = lgb.Dataset(X_test, label=y_test, reference=train_data)
4.3. Xây dựng và huấn luyện mô hình
Tiếp theo, bạn có thể xác định các tham số của mô hình và tiến hành huấn luyện.
python
# Cài đặt các tham số cho mô hình LightGBM
params = {
‘objective’: ‘binary’, # Mục tiêu là phân loại nhị phân
‘metric’: ‘binary_error’, # Đánh giá theo chỉ số lỗi phân loại nhị phân
‘boosting_type’: ‘gbdt’, # Sử dụng GBDT (Gradient Boosting Decision Tree)
‘num_leaves’: 31, # Số lượng lá cây quyết định
‘learning_rate’: 0.05, # Tốc độ học
‘feature_fraction’: 0.9 # Tỷ lệ đặc trưng sử dụng trong mỗi cây
}
# Huấn luyện mô hình
clf = lgb.train(params,
train_data,
valid_sets=[test_data],
num_boost_round=100, # Số vòng lặp huấn luyện
early_stopping_rounds=10) # Dừng sớm nếu không có cải thiện
>>>Xem thêm:Kiểm Tra Trùng Lặp Văn Bản Dài Với Copyscape: Tầm Quan Trọng và Cách Sử Dụng
4.4. Dự đoán và đánh giá mô hình
Sau khi huấn luyện xong, bạn có thể sử dụng mô hình đã huấn luyện để dự đoán và đánh giá hiệu quả của mô hình.
python
# Dự đoán trên dữ liệu kiểm tra
y_pred = clf.predict(X_test, num_iteration=clf.best_iteration)
# Chuyển đổi giá trị dự đoán thành nhãn phân loại
y_pred_label = (y_pred > 0.5).astype(int)
# Đánh giá độ chính xác
accuracy = accuracy_score(y_test, y_pred_label)
print(f”Accuracy: {accuracy:.4f}”)
>>>Xem thêm: Có Nên Sử Dụng Yoast SEO Không? Ưu Nhược Điểm So Với Rank Math
5. Các tham số quan trọng trong LightGBM
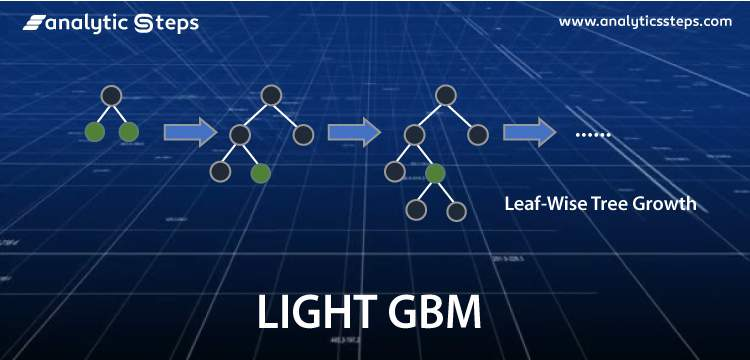
Khi sử dụng LightGBM, bạn có thể điều chỉnh nhiều tham số khác nhau để tối ưu hóa mô hình. Dưới đây là một số tham số quan trọng:
- objective: Chỉ định bài toán bạn muốn giải quyết. Các giá trị phổ biến bao gồm ‘binary’ cho phân loại nhị phân, ‘multiclass’ cho phân loại đa lớp, và ‘regression’ cho bài toán hồi quy.
- metric: Chỉ số đánh giá mà bạn muốn sử dụng. Ví dụ, ‘binary_error’ cho phân loại nhị phân.
- num_leaves: Số lượng lá của cây quyết định, ảnh hưởng đến độ phức tạp của mô hình.
- learning_rate: Tốc độ học, ảnh hưởng đến việc mô hình học nhanh hay chậm.
- feature_fraction: Tỷ lệ đặc trưng được sử dụng trong mỗi cây quyết định.
- bagging_fraction và bagging_freq: Tham số này giúp thực hiện bagging (chọn mẫu ngẫu nhiên từ dữ liệu huấn luyện) để giảm overfitting.
6. Ưu điểm và nhược điểm của LightGBM
6.1. Ưu điểm
- Hiệu suất cao: LightGBM có khả năng xử lý dữ liệu lớn nhanh chóng và hiệu quả.
- Tiết kiệm bộ nhớ: Nhờ vào các thuật toán tối ưu, LightGBM sử dụng ít bộ nhớ hơn so với các thuật toán boosting truyền thống.
- Hỗ trợ tính toán song song: LightGBM có thể huấn luyện các mô hình nhanh chóng bằng cách sử dụng tính toán song song.
- Khả năng tùy chỉnh linh hoạt: LightGBM cung cấp nhiều tham số có thể điều chỉnh để tối ưu hóa mô hình.
6.2. Nhược điểm
- Cần tinh chỉnh tham số: LightGBM yêu cầu phải điều chỉnh nhiều tham số để đạt được hiệu quả tối ưu.
- Không dễ giải thích: LightGBM có thể trở nên khó giải thích đối với những người mới bắt đầu với học máy.
7. Kết luận
LightGBM là một thuật toán mạnh mẽ và hiệu quả cho các bài toán học máy, đặc biệt là trong những trường hợp xử lý dữ liệu lớn và phức tạp. Với khả năng huấn luyện nhanh chóng, tiết kiệm bộ nhớ và tính linh hoạt trong việc điều chỉnh tham số, LightGBM là một công cụ tuyệt vời cho các nhà khoa học dữ liệu và chuyên gia học máy. Hy vọng bài viết này đã giúp bạn hiểu rõ hơn về cách sử dụng LightGBM và cách tối ưu hóa mô hình của mình.
>>>Xem thêm: KeywordTool có mất tiền không? Hướng dẫn cách dùng để nghiên cứu từ khóa dễ sử dụng
Nguyễn Cúc
Bài liên quan
Review khóa học Robotics FUNiX: Lộ trình 7 chặng chuẩn quốc tế
Product Owner Fintech: Bí quyết thiết kế sản phẩm tài chính "không ma sát"

Leanbot là gì? Bộ kit robot giáo dục chuẩn STEM cho thế hệ mới

AIROC - Đấu trường Robotics & AI quốc tế: Nơi thế hệ trẻ Việt Nam vươn tầm thế giới
Học lập trình Python qua Robotics: Từ tư duy code đến Trí tuệ nhân tạo
Nhân viên ngân hàng chuyển sang Fintech: Cần trang bị kỹ năng gì?

Fintech là gì? Toàn cảnh hệ sinh thái Fintech tại Việt Nam 2026
Tại sao Data Analyst là “trái tim” của mọi ứng dụng Fintech?
Đăng ký nhận bản tin




Bình luận (0
)