Data Engineering là gì và quan trọng ra sao?
Các kỹ sư “Dữ liệu” thiết kế và xây dựng các pipeline biến đổi và truyền dữ liệu thành một định dạng để nó sẽ ở trạng thái có thể sử dụng tốt vào thời điểm nó đến tay các nhà khoa học dữ liệu hoặc người dùng cuối khác.
DATA ENGINEERING (KỸ THUẬT DỮ LIỆU) LÀ GÌ?
Kỹ sư là người thiết kế và xây dựng mọi thứ. Các kỹ sư “Dữ liệu” thiết kế và xây dựng các pipeline biến đổi và truyền dữ liệu thành một định dạng để nó sẽ ở trạng thái có thể sử dụng tốt vào thời điểm nó đến tay các nhà khoa học dữ liệu hoặc người dùng cuối khác. Các pipeline này cần lấy dữ liệu từ nhiều nguồn khác nhau và thu thập chúng thành một warehouse (kho dữ liệu) duy nhất biểu diễn dữ liệu một cách đồng nhất, là nguồn sự thật duy nhất.
Nghe thì có vẻ đơn giản, nhưng chúng lại đòi hỏi rất nhiều kỹ năng hiểu biết về dữ liệu. Đó là lý do tại sao lại thiếu hụt nhiều kỹ sư dữ liệu đến vậy và có những nhầm lẫn về vai trò này. Hình dưới đây là một ví dụ về các hoạt động liên quan đến Data Engineering (DE).
LOOKING TO HIRE DATA ENGINEERS? TÌM KIẾM KỸ SƯ DỮ LIỆU?
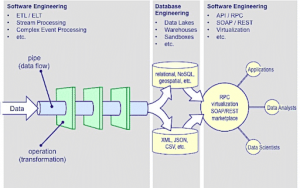
Các hoạt động DE (nguồn: Eckerson Group)
Monica Rogati, một đối tác cổ phần tại Data Collective đã tạo ra một hệ thống phân cấp nhu cầu khoa học dữ liệu nổi tiếng hiện giờ. Hệ thống này mô tả vị trí của DE trong lộ trình trở thành tổ chức khoa học dữ liệu/hoạt động dựa trên AI.
Vai trò của Kỹ sư dữ liệu hiện ở cấp độ 2 và 3. Điều đáng chú ý là cấp độ “thu thập” dưới cùng ngày càng lớn hơn, do đó đẩy mạnh nhu cầu về Kỹ sư dữ liệu hơn.
NHU CẦU (LỚN) VỀ KỸ SƯ DỮ LIỆU
Các nhà khoa học dữ liệu là một nhóm chuyên gia chuyên nghiệp, đón nhận nhiều chú ý và cường điệu. Tuy nhiên, trong vài tháng qua, chúng tôi nhận thấy mối quan tâm ngày càng tăng liên quan đến việc sử dụng nền tảng kiểm thử kỹ năng chuyên môn đối với các vai trò kỹ thuật dữ liệu.
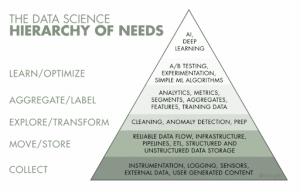
DE chủ yếu rơi vào cấp độ 2 và 3

Việc làm liên quan đến Data engineering tăng 38% trong năm 2019
Chúng tôi thấy được sự gia tăng về nhu cầu kiểm thử kỹ năng Kỹ sư dữ liệu. Báo cáo về các công việc nổi bật năm 2020 của LinkedIn và Báo cáo về vị thế của kỹ sư phần mềm năm 2019 từ Hired đã xếp hạng các vị trí Kỹ sư dữ liệu cùng với với Nhà khoa học dữ liệu và Kỹ sư học máy.
Tuy nhiên, đối với một số công ty, đặc biệt là những công ty vẫn đang đi tìm chỗ đứng của mình trong ngành Data Science hoặc AI, không phải lúc nào họ cũng rõ data engineering là gì, Kỹ sư dữ liệu đóng vai trò gì trong nhóm phân tích và cần những kỹ năng nào (nên được kiểm tra) để đảm nhận công việc.
Vì vậy, trong bài viết ngắn gọn này, chúng tôi sẽ trả lời câu hỏi “data engineering” là gì, giải thích lý do tại sao ngày nay nó được đông đảo mọi người công nhận là cực kỳ quan trọng cũng như vai trò và bộ kỹ năng cần thiết mà một Kỹ sư dữ liệu cần có. Cần lưu ý tới định nghĩa về data engineering và những nhiệm vụ mà một Kỹ sư dữ liệu cần thực hiện để tiếp tục phát triển, cũng hãy ghi nhớ bản tóm tắt này.
DATA ENGINEERING CÓ TỪ BAO GIỜ?
Nhiều người cho rằng data engineering đã tồn tại hơn một thập kỷ, cũng có thể là một vài thập kỷ kể từ khi database (cơ sở dữ liệu), Microsoft SQL Server và ETL ra đời. Một số người thì cho rằng nó đã tồn tại kể từ khi IBM phổ biến các hệ thống quản lý cơ sở dữ liệu vào những năm 1970. Cùng với đó, chúng tôi sẽ đính kèm một bản tóm tắt lịch sử ngắn gọn.
Trong những năm 1980, thuật ngữ “information engineering (kỹ thuật thông tin)” được đưa ra để mô tả phần lớn thiết kế cơ sở dữ liệu và bao gồm kỹ thuật phần mềm trong phân tích dữ liệu. Sau sự nổi lên của Internet vào những năm 1990 và 2000, “big data” đã ra đời. Tuy nhiên, vào thời điểm đó, DBA, các nhà phát triển SQL và các chuyên gia CNTT làm việc trong lĩnh vực này không được gắn mác “Kỹ sư dữ liệu”.
Vậy tại sao lại có cái tên mới này?
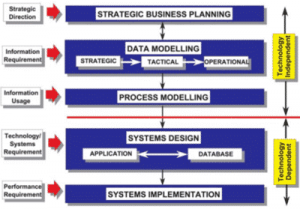
Lược đồ về “kỹ thuật thông tin” theo định hướng kinh doanh của Clive Finkelstein, người đã đặt ra thuật ngữ này
Tóm lại, rất nhiều thay đổi lớn về công nghệ đã xảy ra làm gia tăng khối lượng, sự đa dạng và tốc độ của big data. Khoảng năm 2011, thuật ngữ “Kỹ sư dữ liệu” bắt đầu xuất hiện trong các vòng kết nối của các công ty định hướng dữ liệu mới như Facebook và AirBnB. Dựa trên dữ liệu thời gian thực có giá trị tiềm năng, những kỹ sư phần mềm tại các công ty này cần phát triển các công cụ để xử lý tất cả dữ liệu một cách nhanh chóng và chính xác.
Thuật ngữ “data engineering” được phát triển để mô tả vai trò dịch chuyển từ việc sử dụng các công cụ ETL truyền thống và phát triển các công cụ của riêng mình nhằm xử lý khối lượng dữ liệu ngày càng tăng. Khi big data phát triển, “data engineering” được sử dụng để mô tả một loại kỹ thuật phần mềm tập trung sâu vào data – data infrastructure (dữ liệu – cơ sở hạ tầng dữ liệu), data warehousing (kho dữ liệu), data mining (thăm dò dữ liệu), data modeling (mô hình hóa dữ liệu), data crunching và metadata management (quản lý siêu dữ liệu).
NGUYÊN NHÂN DẪN ĐẾN NHU CẦU VỀ DATA ENGINEERING NHƯ HIỆN NAY?
Có thể bạn đã nghe/đọc về nghiên cứu của Gartner vào năm 2017 rằng 85% dự án big data thất bại phần lớn là do thiếu cơ sở hạ tầng dữ liệu đáng tin cậy. Dữ liệu không đủ tin cậy để làm cơ sở cho các quyết định kinh doanh quan trọng. Cho tới năm 2019, mọi thứ chưa được cải thiện. CTO của IBM cho biết 87% các dự án data science không bao giờ được đưa vào production. Gartner lặp lại dự đoán của mình rằng hiện chỉ 80% dự án sẽ thất bại. Báo cáo của New Vantage đã đưa ra các số liệu thống kê tương tự.
Vậy tại sao lại như vậy?
Trong thập kỷ qua, hầu hết các công ty đã hoàn thành quá trình chuyển đổi kỹ thuật số. Điều này đã tạo ra khối lượng không tưởng của các loại dữ liệu mới, dữ liệu phức tạp hơn nhiều với tần suất cao hơn. Mặc dù trước đây rõ ràng chỉ cần các Nhà khoa học dữ liệu là đủ để hiểu tất cả, nhưng hiển nhiên vẫn cần một vị trí giúp sắp xếp và đảm bảo chất lượng, bảo mật và tính khả dụng của dữ liệu để các Nhà khoa học dữ liệu tiến hành công việc của họ.
Vì vậy, từ những ngày đầu của phân tích dữ liệu lớn, Các nhà khoa học dữ liệu thường được kỳ vọng sẽ xây dựng cơ sở hạ tầng và quy trình dữ liệu cần thiết để thực hiện công việc của họ. Điều này không nhất thiết phải có trong bộ kỹ năng hoặc kỳ vọng của họ đối với công việc. Kết quả là việc mô hình hóa dữ liệu không được thực hiện một cách chính xác. Sẽ có những việc dư thừa và không nhất quán trong việc sử dụng dữ liệu giữa các Nhà khoa học dữ liệu. Những loại vấn đề này đã khiến các công ty không thể trích xuất giá trị tối ưu từ các dự án dữ liệu của họ, cho nên họ gặp thất bại. Nó cũng dẫn đến việc tỷ lệ thu nhập cao của Nhà khoa học dữ liệu vẫn còn tồn tại cho đến ngày nay.
Ngày nay, với ảnh hưởng mạnh mẽ của chuyển đổi kỹ thuật số doanh nghiệp, Internet of Things và cuộc đua dựa trên AI, rõ ràng các công ty cần rất nhiều Kỹ sư dữ liệu để cung cấp nền tảng cho các sáng kiến khoa học dữ liệu thành công.
Đây là lý do tại sao chúng ta sẽ tiếp tục thấy được vai trò của Kỹ sư dữ liệu ngày càng quan trọng và rộng mở hơn. Các công ty cần những nhóm gồm những người có trọng tâm duy nhất là xử lý dữ liệu để từ đó, khai thác giá trị.
MỐI QUAN HỆ VÀ SỰ KHÁC BIỆT GIỮA NHÀ KHOA HỌC DỮ LIỆU VÀ KỸ SƯ DỮ LIỆU
Có khá nhiều bài viết về mối quan hệ giữa hai vị trí này, vì vậy chúng tôi sẽ đề cập ngắn gọn thôi. Trước đây, các công ty nghĩ rằng họ có thể để nhà khoa học dữ liệu thực hiện vai trò của Kỹ sư dữ liệu. Đây là nguyên nhân dẫn đến “unicorn effect (hiệu ứng kỳ lân)” và sự thiếu hụt trong việc tuyển dụng Nhà khoa học dữ liệu.
Một số nhà khoa học dữ liệu cũng tự cho rằng mình có thể làm công việc của Kỹ sư dữ liệu. Nhiều người không đạt theo tiêu chuẩn – hãy xem hình ảnh từ O’Reilly.com.
Ngày nay, khối lượng và tốc độ dữ liệu đã thúc đẩy Nhà khoa học dữ liệu và Kỹ sư dữ liệu trở thành hai vai trò riêng biệt và tách biệt, mặc dù giữa họ vẫn có những điểm tương đồng.
Hiện nay, các công ty đã nhận định rộng rãi rằng cần cả Nhà khoa học dữ liệu và Kỹ sư dữ liệu trong một nhóm phân tích nâng cao. Khá khó để thực hiện bất kỳ dự án khoa học dữ liệu có ý nghĩa nào mà không có Kỹ sư dữ liệu hỗ trợ. Có sự hợp tác thường xuyên giữa Kỹ sư dữ liệu và Nhà khoa học dữ liệu, tuy nhiên, các kỹ năng trọng điểm và kiến thức về các công cụ lại khác nhau.
Các nhà khoa học dữ liệu tập trung vào phân tích dữ liệu nâng cao, được tạo và lưu trữ trong cơ sở dữ liệu của doanh nghiệp. Kỹ sư dữ liệu thiết kế, quản lý và tối ưu hóa luồng dữ liệu với các cơ sở dữ liệu đó trong toàn tổ chức. Vì vậy, các nhà khoa học dữ liệu sẽ có kỹ năng chuyên môn về toán học và thống kê, R, thuật toán và các kỹ thuật học máy. Các kỹ sư dữ liệu sẽ thông thạo hơn về SQL, MySQL và NoSQL, các framework và công nghệ, kiến trúc dựa trên Cloud, chẳng hạn như agile và scrum.
Cả hai đều biết Python, các kỹ thuật trực quan hóa và có chung các ngôn ngữ mã hóa khác.
KỸ SƯ DỮ LIỆU CẦN NHỮNG KỸ NĂNG NÀO?
Kỹ sư dữ liệu phải có kỹ năng chuyên biệt trong việc tạo các giải pháp phần mềm xung quanh dữ liệu. Đồng thời, có lẽ không thực tế lắm khi kỳ vọng Kỹ sư dữ liệu sẽ quen thuộc với nhiều loại công cụ và công nghệ – từ 10 đến 30. Và những công cụ này liên tục thay đổi. Hơn nữa, nó còn thay đổi theo ngành.
Một số công cụ, chẳng hạn như SQL thì luôn như vậy. Những công vụ khác như Scala đang giảm sự ưa chuộng theo thời gian. Còn những công cụ như AWS thì lại đang tăng nhanh về nhu cầu.
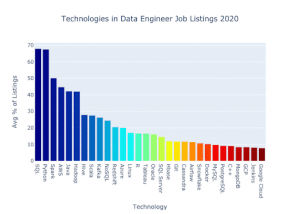
Jeff Hale – tác giả xuất bản và người hướng dẫn về các chủ đề khoa học dữ liệu và kỹ thuật dữ liệu gần đây đã tiến hành phân tích về các kỹ năng được yêu cầu nhiều nhất đối với Kỹ sư dữ liệu trên ba nền tảng công việc. Dưới đây là tóm tắt của ông ấy về 10 kỹ năng công nghệ hàng đầu mà kỹ sư dữ liệu cần có.
Kỹ sư dữ cần nắm được nhiều kỹ năng, và độ phức tạp của một số kỹ năng trong số đó khiến cho việc xác định người phù hợp với công việc trở nên khó khăn hơn.
Các yêu cầu để đảm nhận vị trí kỹ sư dữ liệu đã gia tăng khá nhiều trong vài năm qua. Đó là lý do tại sao chúng tôi đề xuất đối với khoa học dữ liệu, hãy coi “Kỹ sư dữ liệu” là một nhóm gồm những người có portfolio (tập hợp các dự án) thể hiện kỹ năng kỹ thuật dữ liệu. Bạn ưu tiên cái nào còn tùy thuộc vào rất nhiều thứ.
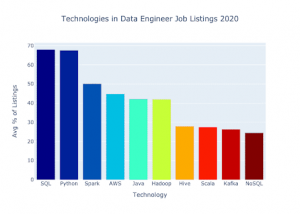
Như đã nói, phạm vi kỹ năng quan trọng gồm:
- Foundation software engineering (Kỹ thuật phần mềm cơ bản) –Agile, devOps, thiết kế kiến trúc, kiến trúc hướng dịch vụ.
- Distributed systems (Hệ thống phân tán) – Gồm các kỹ năng kỹ sư phần mềm và kỹ năng kiến trúc phần mềm.
- Open Frameworks –Apache Spark, Hadoop, có thể là Hive, MapReduce, Kafka, …
- SQL –Đây là cơ sở dữ liệu chính, trước giờ vẫn như vậy.
- Programming – Python là ngôn ngữ được ưa chuộng khi làm việc với dữ liệu. Mặt khác, dù Java vẫn được sử dụng rộng rãi nhưng đã không còn được phần lớn các nhà khoa học và kỹ sư dữ liệu ưa chuộng. Scala là một ngôn ngữ khác làm cơ sở cho Apache Spark và Kafka.
- Pandas – Là một thư viện Python giúp làm sạch và thao tác dữ liệu.
- Visualization/dashboards
- Cloud platforms – AWS có lẽ là bộ kỹ năng Cloud phổ biến nhất mà các Kỹ sư dữ liệu cần biết, xếp sau là Google Cloud Data Engineering và Microsoft Azure.
- Analytics –Dù đây là lĩnh vực chủ yếu của các nhà khoa học dữ liệu, nhưng kỹ năng phân tích thống kê hoặc hiểu biết một số nguyên tắc toán học khác nhau hoặc các nguyên tắc xác suất khá cần thiết để thao tác dữ liệu đúng cách, để những người đang thực hiện phân tích phân đoạn cuối về nó truy cập được.
- Data modeling – Kiến thức về mô hình hóa dữ liệu hiện nay khá quan trọng, Kỹ sư dữ liệu cần biết cách sắp xếp cấu trúc bảng, phân vùng, nơi cần chuẩn hóa và không chuẩn hóa dữ liệu trong warehouse, … và cách suy nghĩ về việc truy xuất một số thuộc tính.
Khá nhiều thứ, nhưng đó là để chứng minh quan điểm của Jeff Hale về top 30 công nghệ hàng đầu mà Kỹ sư dữ liệu cần có.
Với số lượng đa dạng như vậy, không có gì ngạc nhiên khi một số công ty vẫn đang vật lộn để tìm ra kỹ thuật dữ liệu chính xác, cách kiểm tra và thuê Kỹ sư dữ liệu.
Nguyễn Hải Nam
Dịch từ bài viết Data engineer
Bài liên quan
Đào tạo AI nội bộ cho doanh nghiệp: Bắt đầu từ kỹ năng nào?
Mô hình FUNiX Way trong đào tạo nhân sự 4.0: Khác gì cách học truyền thống?
App Inventor và Robotics: Tự thiết kế ứng dụng điều khiển Robot trên điện thoại
Lộ trình học lập trình Robot cho học sinh từ lớp 6 đến lớp 12
Robotics là gì? Tại sao học sinh cần học Robotics từ sớm trong năm 2026?
Review khóa học Fintech FUNiX: Đào tạo thực chiến 7 tháng cho người mới
Ứng dụng GenAI trong phân tích dữ liệu và vận hành Fintech
Quản trị rủi ro Fintech: Cách AI bảo vệ dòng tiền và ngăn chặn gian lận
Đăng ký nhận bản tin




Bình luận (0
)