Kỹ thuật dữ liệu là gì và nó có phù hợp với bạn không?
Big Data, Cloud Data, dữ liệu đào tạo AI, dữ liệu nhận dạng cá nhân, dữ liệu ở xung quanh bạn và đang phát triển mỗi ngày. Kỹ thuật phần mềm phát triển, đi kèm theo đó là kỹ thuật dữ liệu, một ngành con tập trung trực tiếp vào việc vận chuyển, chuyển đổi và lưu trữ dữ liệu.
Có lẽ bạn đã xem các tin tuyển dụng về Big Data và bị hấp dẫn bởi toàn cảnh của việc xử lý dữ liệu ở quy mô petabyte/ petabyte-scale data. Có thể bạn tò mò về cách generative adversarial networks tạo ra hình ảnh thực tế từ underlying data. Có thể bạn chưa bao giờ nghe nói về kỹ thuật dữ liệu nhưng lại quan tâm đến cách các nhà phát triển xử lý lượng lớn dữ liệu, thứ cần thiết cho hầu hết các ứng dụng ngày nay như thế nào.
Bất kể bạn thuộc nhóm nào, bài viết này là dành cho bạn. Bạn sẽ có cái nhìn tổng quan về lĩnh vực này, bao gồm cả kỹ thuật dữ liệu là gì và những yêu cầu công việc mà nó đòi hỏi.
Trong bài viết này, bạn sẽ tìm hiểu về:
- Thực trạng của lĩnh vực kỹ thuật dữ liệu.
- Kỹ thuật dữ liệu được sử dụng như thế nào trong ngành công nghiệp.
- Khách hàng của các kỹ sư dữ liệu là ai.
- Việc gì thuộc và không thuộc lĩnh vực kỹ thuật dữ liệu.
- Làm thế nào để quyết định xem bạn có muốn theo đuổi kỹ thuật dữ liệu như một ngành học hay không.
Để bắt đầu, bạn sẽ trả lời một trong những câu hỏi cấp bách nhất về lĩnh vực này: Kỹ sư dữ liệu làm gì?
Kỹ sư dữ liệu làm gì?
Kỹ thuật dữ liệu là một lĩnh vực khá rộng với nhiều công việc khác nhau. Trong nhiều doanh nghiệp, nó thậm chí có thể không có một nhiệm vụ cụ thể nào. Do đó, có lẽ, trước tiên bạn nên xác định các mục tiêu của kỹ thuật dữ liệu, sau đó thảo luận về loại công việc nào mang lại những outcome mong đợi.
Mục tiêu cuối cùng của kỹ thuật dữ liệu là cung cấp luồng dữ liệu nhất quán, có tổ chức, làm cho công việc hướng dữ liệu có thể hoạt động hiệu quả, chẳng hạn như:
- Đào tạo mô hình học máy
- Thực hiện phân tích dữ liệu khám phá
- Đưa các dữ liệu bên ngoài vào các trường dữ liệu trong ứng dụng
Luồng dữ liệu này có thể thu được theo bất kỳ cách nào, các bộ công cụ, kỹ thuật và kỹ năng cần thiết sẽ rất khác nhau giữa các nhóm, tổ chức và outcome mong muốn. Tuy nhiên, một pattern phổ biến là data pipeline. Đây là một hệ thống bao gồm các chương trình độc lập thực hiện các hoạt động khác nhau trên dữ liệu đầu vào hoặc dữ liệu được thu thập.
Các data pipeline thường được phân phối trên nhiều máy chủ:
Hình ảnh này là một ví dụ đơn giản về data pipeline, giúp cho bạn mường tượng một cách cơ bản nhất về một kiến trúc mà bạn có thể gặp. Bạn sẽ thấy một biểu đồ phức tạp hơn ở phía dưới.
Dữ liệu có thể đến từ bất kỳ nguồn nào:
- Thiết bị Internet of Things
- Máy đo từ xa trên xe
- Nguồn cấp dữ liệu bất động sản
- Hoạt động bình thường của người dùng trên một ứng dụng web
- Bất kỳ công cụ thu thập hoặc đo lường nào khác mà bạn có thể nghĩ đến
Tùy thuộc vào bản chất của các nguồn này, incoming data sẽ được xử lý theo dạng real-time streams hoặc xử lý dữ liệu theo batch.
Pipeline mà dữ liệu chạy qua là nhiệm vụ của kỹ sư dữ liệu, các nhóm kỹ sư dữ liệu chịu trách nhiệm thiết kế, xây dựng, bảo trì, mở rộng cơ sở hạ tầng, hỗ trợ các pipeline dẫn dữ liệu. Họ cũng có thể chịu trách nhiệm về incoming data hoặc thường xuyên hơn là data model và cách dữ liệu đó được lưu trữ.
Nếu bạn nghĩ về data pipeline như một loại ứng dụng thì, kỹ thuật dữ liệu bắt đầu giống như những ngành kỹ thuật phần mềm khác.
Nhiều nhóm kỹ sư cũng đang tiến tới xây dựng data platforms. Trong nhiều doanh nghiệp, sẽ không đáp ứng đủ nhu cầu nếu chỉ một pipeline duy nhất lưu incoming data vào SQL database. Các doanh nghiệp lớn có nhiều đội ngũ kỹ sư, với mỗi chuyên môn cần có các cấp độ truy cập khác nhau vào các loại dữ liệu khác nhau.
Ví dụ: nhóm Trí tuệ nhân tạo (AI) có thể cần các quyền để gắn nhãn và phân chia dữ liệu đã được làm sạch. Các nhóm Trí tuệ doanh nghiệp (BI) có thể cần quyền truy cập dễ dàng để tổng hợp dữ liệu và xây dựng data visualizations. Các nhóm khoa học dữ liệu có thể cần quyền truy cập cấp cơ sở dữ liệu để khám phá dữ liệu một cách chính xác.
Nếu bạn đã quen với việc phát triển web, thì bạn có thể thấy cấu trúc này tương tự như mẫu thiết kế Model-View-Controller (MVC) design pattern. Với MVC, các kỹ sư dữ liệu chịu trách nhiệm về mô hình, các nhóm AI hoặc BI làm việc trên các chế độ xem và tất cả các nhóm cộng tác trên một bộ điều khiển. Việc xây dựng các nền tảng dữ liệu nhằm đáp ứng tất cả những nhu cầu này đang được ưu tiên trong các doanh nghiệp, nơi có các nhóm kỹ sư được phân chia dựa vào quyền truy cập dữ liệu.
Bạn đã nắm được kỹ sư dữ liệu làm gì và họ gắn kết với khách hàng của họ như thế nào, sẽ rất hữu ích nếu bạn tìm hiểu thêm về những khách hàng đó và trách nhiệm của các kỹ sư dữ liệu đối với họ.
Kỹ sư dữ liệu có trách nhiệm gì?
Khách hàng của các kỹ sư dữ liệu cũng đa dạng như những kỹ năng và outcomes của chính các nhóm kỹ thuật dữ liệu. Bất kể bạn theo đuổi lĩnh vực nào, khách hàng của bạn sẽ luôn xác định được bạn giải quyết vấn đề gì và bạn giải quyết chúng như thế nào.
Trong phần này, bạn sẽ tìm hiểu về một số khách hàng phổ biến của các nhóm kỹ thuật dữ liệu thông qua lăng kính nhu cầu dữ liệu của họ:
- Nhóm khoa học dữ liệu và AI
- Nhóm phân tích hoặc trí tuệ doanh nghiệp
- Nhóm sản phẩm
Trước khi bất kỳ nhóm nào trong số này có thể hoạt động hiệu quả, một số yêu cầu nhất định phải được đáp ứng. Đặc biệt, dữ liệu phải:
- Được định tuyến/ đường truyền đáng tin cậy vào hệ thống lớn hơn
- Được chuẩn hóa thành mô hình dữ liệu phù hợp
- Được làm sạch để lấp đầy những khoảng trống quan trọng
- Tất cả các thành viên có liên quan đều có thể truy cập được
Những yêu cầu này được trình bày chi tiết, đầy đủ hơn trong bài viết The AI Hierarchy of Needs của Monica Rogarty. Là một kỹ sư dữ liệu, bạn có trách nhiệm giải quyết các nhu cầu về dữ liệu của khách hàng. Tuy nhiên, bạn sẽ sử dụng nhiều phương pháp khác nhau để đáp ứng quy trình công việc của họ.
Luồng dữ liệu
Để làm bất cứ điều gì với dữ liệu trong hệ thống, trước tiên bạn phải đảm bảo rằng dữ liệu đó có thể đi vào và đi qua hệ thống một cách chuẩn xác. Đầu vào có thể là hầu hết các loại dữ liệu mà bạn có thể tưởng tượng, bao gồm:
- Dữ liệu định dạng JSON hoặc XML
- Hàng loạt các video được cập nhật mỗi giờ
- Dữ liệu xét nghiệm máu theo tháng.
- Các nhóm hình ảnh đã được gắn nhãn theo tuần
- Phép đo lường từ xa thu được từ cảm biến
Các kỹ sư dữ liệu thường chịu trách nhiệm sử dụng dữ liệu này, thiết kế một hệ thống có thể lấy dữ liệu này làm đầu vào, từ một hoặc nhiều nguồn, biến đổi dữ liệu, sau đó lưu trữ cho khách hàng của họ. Các hệ thống này thường được gọi là pipeline ETL, viết tắt của extract – chiết xuất, transform – biến đổi và load – tải.
Luồng dữ liệu chủ yếu thuộc bước trích xuất. Nhưng trách nhiệm của kỹ sư dữ liệu không chỉ dừng lại ở việc kéo dữ liệu vào pipeline. Họ phải đảm bảo rằng pipeline đủ mạnh để luôn đối mặt với các dữ liệu không mong muốn hoặc không đúng định dạng, các nguồn dữ liệu ngoại tuyến và các lỗi nghiêm trọng. Thời gian hoạt động rất quan trọng, đặc biệt khi bạn đang sử dụng live hoặc time-sensitive data( dữ liệu trực tiếp hoặc dữ liệu nhạy cảm với thời gian).
Trách nhiệm duy trì luồng dữ liệu của bạn sẽ khá nhất quán cho dù khách hàng của bạn là ai. Tuy nhiên, một số khách hàng có thể yêu cầu cao hơn những khách hàng khác, đặc biệt khi khách hàng là một ứng dụng được xây dựng dựa vào dữ liệu luôn được cập nhật theo nguyên tắc thời gian thực.
Chuẩn hóa và mô hình hóa dữ liệu
Dữ liệu chảy về một hệ thống là rất tốt. Tuy nhiên, tại một số thời điểm, dữ liệu cần phải tuân theo một số tiêu chuẩn về kiến trúc. Chuẩn hóa dữ liệu bao gồm các tác vụ giúp người dùng dễ truy cập dữ liệu hơn. Điều này bao gồm nhưng không bị giới hạn ở các bước sau:
- Loại bỏ các bản sao (deduplication – khử trùng lặp)
- Chỉnh sửa dữ liệu xung đột
- Đồng dạng dữ liệu với mô hình dữ liệu cụ thể
Các quá trình này có thể xảy ra ở các giai đoạn khác nhau. Ví dụ: hãy tưởng tượng bạn làm việc trong một doanh nghiệp lớn với các nhà khoa học dữ liệu và nhóm BI, cả hai đều dựa vào dữ liệu của bạn. Bạn có thể lưu trữ dữ liệu phi cấu trúc trong một data lake, để các nhà khoa học dữ liệu (khách hàng của bạn) sử dụng và phân tích dữ liệu khám phá. Bạn cũng có thể lưu trữ dữ liệu được chuẩn hóa trong relational database hoặc data warehouse được xây dựng có mục đích, để nhóm BI sử dụng trong các báo cáo của mình.
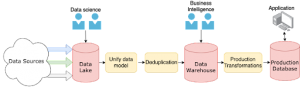
Bạn có thể có nhiều hoặc một vài nhóm khách hàng hoặc có thể một ứng dụng sử dụng dữ liệu của bạn. Hình ảnh bên dưới cho thấy một phiên bản đã sửa đổi so với ví dụ pipeline trước đó, làm nổi bật các giai đoạn khác nhau mà tại đó một số nhóm nhất định có thể truy cập vào dữ liệu:
Trong hình ảnh này, bạn thấy một đường dẫn dữ liệu giả định và các giai đoạn mà tại đó các nhóm khách hàng khác nhau đang hoạt động.
Nếu khách hàng của bạn là một product team, thì một mô hình dữ liệu được kiến trúc tốt là rất quan trọng. Một mô hình dữ liệu hiệu quả có thể tạo nên sự khác biệt giữa một ứng dụng chạy chậm và hầu như không phản hồi, so với một ứng dụng chạy cứ như thể nó đã biết người dùng muốn truy cập dữ liệu nào. Những loại quyết định này thường là kết quả của sự hợp tác giữa các product team và data engineering team.
Chuẩn hóa dữ liệu và mô hình hóa thường là một phần của bước chuyển đổi của ETL, nhưng chúng không phải là những bước duy nhất trong danh mục này. Một bước biến đổi phổ biến khác đó là làm sạch dữ liệu.
Làm sạch dữ liệu
Làm sạch dữ liệu đi đôi với chuẩn hóa dữ liệu. Một số thậm chí còn coi việc chuẩn hóa dữ liệu là một tập hợp con của việc làm sạch dữ liệu. Trong khi quá trình chuẩn hóa dữ liệu chủ yếu tập trung vào việc làm cho các dữ liệu khác nhau tuân theo một số mô hình dữ liệu nhất định, thì việc làm sạch dữ liệu bao gồm cả hành động giúp dữ liệu đồng nhất và hoàn chỉnh hơn, bao gồm:
- Chuyển đổi những dữ liệu giống nhau sang một kiểu duy nhất (ví dụ: các chuỗi trong một trường số nguyên nhất định phải là số nguyên strings in an integer field to be integers)
- Đảm bảo dates ở cùng một định dạng
- Điền vào các trường còn thiếu nếu có thể
- Ràng buộc các giá trị của một trường trong một phạm vi nhất định
- Xóa dữ liệu bị hỏng hoặc không sử dụng được
Làm sạch dữ liệu có thể được đưa vào các bước hợp nhất dữ liệu và khử trùng lặp trong sơ đồ trên. Tuy nhiên, trên thực tế, khối lượng công việc xử lý trong mỗi bước trong số đó đều rất lớn, có thể bao gồm thêm các giai đoạn và quy trình riêng lẻ.
Các hành động cụ thể mà bạn thực hiện để làm sạch dữ liệu sẽ phụ thuộc vào đầu vào, mô hình dữ liệu và outcome mong muốn. Tuy nhiên, tầm quan trọng của làm sạch dữ liệu là không đổi:
- Các nhà khoa học dữ liệu cần nó để thực hiện các phân tích chính xác.
- Các kỹ sư học máy cần nó để xây dựng các mô hình tổng quát và chính xác.
- Các nhà phân tích kinh doanh cần nó để cung cấp các báo cáo và dự báo chính xác cho doanh nghiệp.
- Product teams cần nó để đảm bảo sản phẩm của họ không bị lỗi hoặc cung cấp thông tin bị lỗi cho người dùng.
Trách nhiệm làm sạch dữ liệu thuộc về rất nhiều bộ phận, tổ chức tổng thể và các ưu tiên của tổ chức đó. Là một kỹ sư dữ liệu, bạn nên cố gắng tự động hóa việc làm sạch dữ liệu càng nhiều càng tốt, thường xuyên kiểm tra ngẫu nhiên đối với incoming data và dữ liệu được lưu trữ.
Truy cập dữ liệu
Khả năng truy cập dữ liệu không được chú ý nhiều như chuẩn hóa và làm sạch dữ liệu, nhưng đây được cho là một trong những nhiệm vụ quan trọng hơn của nhóm kỹ thuật dữ liệu lấy khách hàng làm trọng tâm.
Khả năng truy cập dữ liệu đề cập đến mức độ dễ dàng của dữ liệu mà khách hàng có thể truy cập và hiểu. Điều này được xác định khác nhau tùy thuộc vào khách hàng:
- Data science teamscó thể chỉ cần dữ liệu có thể truy cập được bằng một số loại ngôn ngữ truy vấn.
- Analytics teamscó thể thích dữ liệu được nhóm theo một số chỉ số, có thể truy cập thông qua các truy vấn cơ bản hoặc giao diện báo cáo.
- Product teams thường sẽ muốn dữ liệu có thể truy cập được thông qua các truy vấn trực tiếp và đơn giản, không thay đổi thường xuyên, hướng đến hiệu suất và độ tin cậy của sản phẩm.
Bởi vì các doanh nghiệp lớn cung cấp cho các nhóm này và những nhóm khác cùng một dữ liệu, nhiều trong số đó đã chuyển sang phát triển các nền tảng nội bộ của riêng họ cho các nhóm. Một ví dụ điển hình về điều này là dịch vụ đặt xe Uber, đã chia sẻ nhiều chi tiết về nền tảng dữ liệu lớn ấn tượng của mình impressive big data platform.
Trên thực tế, nhiều kỹ sư dữ liệu đang nhận thấy rằng họ đang dần trở thành platform engineers, nhấn mạnh hơn nữa tầm quan trọng của các kỹ năng kỹ thuật dữ liệu đối với các doanh nghiệp định hướng dữ liệu. Vì khả năng truy cập dữ liệu gắn chặt với cách dữ liệu được lưu trữ, nên đây là thành phần chính của bước load trong ETL, đề cập đến cách dữ liệu được lưu trữ để sử dụng về sau.
Bạn đã nắm được một số khách hàng phổ biến của kỹ thuật dữ liệu, biết về nhu cầu của họ, đã đến lúc chúng ta xem xét kỹ hơn những kỹ năng bạn cần phát triển, để giúp giải quyết những nhu cầu đó.
Các kỹ năng phổ biến cần có trong Kỹ thuật dữ liệu
Các kỹ năng của kỹ thuật dữ liệu phần lớn là những kỹ năng bạn cần cho kỹ thuật phần mềm. Tuy nhiên, có một số lĩnh vực mà các kỹ sư dữ liệu có xu hướng tập trung nhiều hơn. Trong phần này, bạn sẽ tìm hiểu về một số kỹ năng quan trọng:
- Các kỹ năng lập trình tổng quát
- Database
- Hệ thống phân tán và kỹ thuật điện toán đám mây
Mỗi loại trong số này sẽ đóng một vai trò quan trọng trong việc giúp bạn trở thành một kỹ sư dữ liệu toàn diện.
Các kỹ năng lập trình tổng quát
Kỹ thuật dữ liệu là một chuyên ngành của kỹ thuật phần mềm, đồng nghĩa với việc các nguyên tắc cơ bản của kỹ thuật phần mềm phải nằm ở đầu danh sách này. Cũng như các chuyên môn kỹ thuật phần mềm khác, kỹ sư dữ liệu phải hiểu các khái niệm thiết kế như DRY (don’t repeat yourself), object-oriented programming, data structures và các thuật toán.
Giống như một số chuyên ngành khác, luôn có một vài ngôn ngữ được ưa dùng. Khi tìm hiểu về chủ đề này, những thứ bạn thấy thường xuyên nhất trong mô tả công việc kỹ thuật dữ liệu là Python, Scala và Java. Điều gì làm cho những ngôn ngữ này trở nên phổ biến như vậy?
Python phổ biến vì nhiều lý do. Phần lớn là vì tính thông dụng của nó. Theo nhiều đánh giá, Python nằm trong số ba ngôn ngữ lập trình phổ biến nhất trên thế giới. Ví dụ: nó xếp thứ hai trong TIOBE Community Indexv vào tháng 11 năm 2020 và thứ ba trong cuộc khảo sát dành cho nhà phát triển của Stack Overflow năm 2020 2020 Developer Survey.
Nó cũng được sử dụng rộng rãi bởi các nhóm học máy và AI. Các nhóm làm việc chặt chẽ với nhau thường cần có khả năng giao tiếp cùng một ngôn ngữ và Python vẫn là ngôn ngữ phổ biến của lĩnh vực này.
Một lý do khác ngoài sự phổ biến của Python là việc sử dụng nó trong các công cụ điều phối như Apache Airflow và các thư viện có sẵn cho các công cụ phổ biến như Apache Spark. Nếu một doanh nghiệp sử dụng một lúc nhiều công cụ như vậy, thì điều cần thiết là phải biết những ngôn ngữ mà họ sử dụng.
Scala cũng khá phổ biến, và giống như Python, điều này một phần là do tính thông dụng của các công cụ sử dụng nó, đặc biệt là Apache Spark. Scala là một ngôn ngữ chức năng chạy trên Máy ảo Java (JVM), giúp nó có thể được sử dụng liền mạch với Java.
Java không phổ biến trong lĩnh vực kỹ thuật dữ liệu, nhưng bạn vẫn sẽ thấy nó trong một số mô tả công việc. Điều này một phần là do tính phổ biến của nó trong các enterprise software stacks và một phần là do khả năng tương tác của nó với Scala. Với việc Scala được sử dụng cho Apache Spark, có nghĩa là một số nhóm cũng sử dụng Java.
Ngoài các kỹ năng lập trình chung, việc làm quen tốt với các công nghệ database là điều cần thiết.
Công nghệ Database
Nếu bạn định di chuyển dữ liệu, thì bạn sẽ phải thường xuyên sử dụng đến database. Nhìn chung, bạn có thể chia các công nghệ database thành hai loại: SQL và NoSQL.
Cơ sở dữ liệu SQL là hệ thống quản lý cơ sở dữ liệu quan hệ (RDBMS), giúp mô hình hóa các mối quan hệ và được tương tác với nhau bằng cách sử dụng Structured Query Language (SQL – Ngôn ngữ truy vấn có cấu trúc). Chúng thường được sử dụng để lập mô hình dữ liệu thông qua việc xác định các mối quan hệ dữ liệu, chẳng hạn như dữ liệu đơn đặt hàng của khách hàng.
Lưu ý: Nếu bạn muốn tìm hiểu thêm về SQL và cách tương tác với cơ sở dữ liệu SQL bằng Python, hãy tham khảo thêm Introduction to Python SQL Libraries.
NoSQL thường có nghĩa là “everything else”. Đây là những database thường lưu trữ dữ liệu phi quan hệ, chẳng hạn như:
- Key-value stores như Redis hoặc AWS’s DynamoDB
- Document stores như MongoDB hoặc Elasticsearch
- Cơ sở dữ liệu đồ thị như Neo4j
- Các kho dữ liệu khác, ít phổ biến hơn
Mặc dù bạn không bắt buộc phải biết thông tin chi tiết của tất cả các công nghệ cơ sở dữ liệu, nhưng bạn nên hiểu ưu và nhược điểm của các hệ thống khác nhau này và có thể tìm hiểu nhanh một hoặc hai trong số chúng.
Các hệ thống mà các kỹ sư dữ liệu làm việc ngày càng được đặt nhiều trên Cloud và các data pipeline thường được phân phối trên nhiều máy chủ hoặc cụm, cho dù là private cloud hay không. Do đó, một kỹ sư dữ liệu tiềm năng nên hiểu các hệ thống phân tán và kỹ thuật điện toán đám mây.
Hệ thống phân tán và Kỹ thuật điện toán đám mây
Một trong những lợi thế chính của công nghệ kỹ thuật dữ liệu, chẳng hạn như quy trình ETL là chúng tự cho phép triển khai các hệ thống phân tán- distributed systems. Một pattern phổ biến là pattern có các phân đoạn độc lập của một pipeline chạy trên các máy chủ riêng biệt, được sắp xếp bởi message queue như RabbitMQ hoặc Apache Kafka.
Điều quan trọng là phải hiểu cách thiết kế của các hệ thống này, lợi ích và rủi ro của chúng là gì và khi nào bạn nên sử dụng chúng.
Các hệ thống này yêu cầu nhiều máy chủ và các nhóm phân tán theo địa lý thường cần quyền truy cập vào dữ liệu mà chúng chứa. Các nhà cung cấp private cloud như Amazon Web Services, Google Cloud và Microsoft Azure là những công cụ cực kỳ phổ biến để xây dựng và triển khai các hệ thống phân tán.
Hiểu biết cơ bản về các dịch vụ chính của các cloud providers cũng như một số công cụ phân tán message phổ biến sẽ giúp bạn tìm được công việc kỹ thuật dữ liệu đầu tiên của mình. Bạn có thể tìm hiểu kỹ hơn về các công cụ này trong công việc đó.
Chúng ra đã tìm hiểu rất nhiều về kỹ thuật dữ liệu là gì. Nhưng vì không có định nghĩa tiêu chuẩn về lĩnh vực này và bởi vì có rất nhiều lĩnh vực liên quan, bạn cũng nên có ý tưởng về những gì không phải là kỹ thuật dữ liệu.
Những gì không phải là kỹ thuật dữ liệu?
Nhiều lĩnh vực liên quan chặt chẽ đến kỹ thuật dữ liệu và khách hàng của bạn thường sẽ là thành viên của những lĩnh vực này. Điều quan trọng là phải biết khách hàng của bạn là ai, từ đó bạn sẽ biết rõ hơn về lĩnh vực này.
Dưới đây là một số lĩnh vực có liên quan chặt chẽ đến kỹ thuật dữ liệu:
- Data Science
- Trí tuệ doanh nghiệp (BI)
- Kỹ thuật Học máy
Trong phần này, bạn sẽ xem xét kỹ hơn các lĩnh vực này, bắt đầu với Data Science.
Data Science
Nếu kỹ thuật dữ liệu bị chi phối bởi cách bạn di chuyển và tổ chức khối lượng dữ liệu khổng lồ, thì Data Science bị chi phối bởi những gì bạn làm với dữ liệu đó.
Các nhà khoa học dữ liệu thường truy vấn, khám phá và cố gắng thu thập các insights từ các tập dữ liệu. Họ có thể viết các tập lệnh một lần- one-off scripts để sử dụng với một tập dữ liệu cụ thể, trong khi các kỹ sư dữ liệu có xu hướng tạo các chương trình có thể tái sử dụng, bằng cách sử dụng các phương pháp kỹ thuật phần mềm.
Nhà khoa học dữ liệu sử dụng các công cụ thống kê như phân cụm k-means clustering và hồi quy regressions cùng với các kỹ thuật học máy. Họ thường làm việc với R hoặc Python và cố gắng thu thập derive insights và dự đoán từ dữ liệu, đưa ra quyết định ở tất cả các cấp của doanh nghiệp.
Các nhà khoa học dữ liệu thường có background về khoa học hoặc thống kê, phong cách làm việc của họ phản ánh điều đó. Họ làm việc trên một dự án để trả lời một câu hỏi nghiên cứu cụ thể, trong khi nhóm kỹ thuật dữ liệu tập trung vào việc xây dựng các sản phẩm nội bộ có thể mở rộng, tái sử dụng và nhanh chóng.
Một ví dụ tuyệt vời là các nhà khoa học dữ liệu có thể tìm thấy câu trả lời về các nghiên cứu trong các công ty công nghệ sinh học và công nghệ y tế, tại đó, họ khám phá dữ liệu về tương tác thuốc, tác dụng phụ, kết quả bệnh án, v.v.
Trí tuệ doanh nghiệp (BI)
Business intelligence tương tự như Data Science, với một vài điểm khác biệt quan trọng. Trong đó Data Science tập trung vào việc dự báo và đưa ra các dự đoán trong tương lai, thì BI tập trung vào việc cung cấp cái nhìn về tình trạng hiện tại của doanh nghiệp.
Cả hai nhóm này đều cộng tác với các nhóm kỹ thuật dữ liệu và thậm chí có thể làm việc từ cùng một nhóm dữ liệu. Tuy nhiên, Business Intelligence liên quan đến việc phân tích hiệu suất kinh doanh và tạo báo cáo từ dữ liệu. Các báo cáo này sau đó giúp ban lãnh đạo đưa ra quyết định ở cấp độ kinh doanh.
Giống như các nhà khoa học dữ liệu, BI teams dựa vào các kỹ sư dữ liệu để xây dựng các công cụ cho phép họ phân tích và báo cáo dữ liệu liên quan đến lĩnh vực trọng tâm của họ.
Kỹ thuật học máy
Kỹ sư học máy là một nhóm khác mà bạn sẽ thường xuyên tiếp xúc. Bạn có thể làm công việc tương tự với họ hoặc thậm chí bạn có thể được đưa vào một nhóm kỹ sư học máy.
Giống như các kỹ sư dữ liệu, kỹ sư ML tập trung hơn vào việc xây dựng phần mềm có thể tái sử dụng và nhiều người trong số học có background về khoa học máy tính. Tuy nhiên, họ ít tập trung hơn vào việc xây dựng ứng dụng mà tập trung nhiều hơn vào việc xây dựng các mô hình học máy hoặc thiết kế các thuật toán mới để sử dụng trong các mô hình.
Lưu ý: Nếu bạn quan tâm đến lĩnh vực máy học, hãy xem lộ trình Học máy với Python Machine Learning With Python.
Các mô hình mà các kỹ sư học máy xây dựng thường được product teams sử dụng trong các sản phẩm hướng tới khách hàng. Dữ liệu mà bạn cung cấp với tư cách là kỹ sư dữ liệu sẽ được sử dụng để huấn luyện các mô hình của họ, giúp công việc của bạn trở thành nền tảng cho khả năng của bất kỳ nhóm học máy nào mà bạn làm việc cùng.
Ví dụ: một kỹ sư học máy có thể phát triển một thuật toán đề xuất mới cho sản phẩm của công ty bạn, trong khi một kỹ sư dữ liệu sẽ cung cấp dữ liệu được sử dụng để đào tạo và kiểm tra thuật toán đó.
Một điều quan trọng cần hiểu là các lĩnh vực bạn đã tìm hiểu ở đây thường không thực sự khác biệt rõ ràng. Những người có nền tảng về Data Science, BI hoặc học máy có thể làm công việc kỹ thuật dữ liệu tại một tổ chức và với tư cách là kỹ sư dữ liệu, bạn có thể được kêu gọi để hỗ trợ các nhóm này trong công việc của họ.
Bạn có thể thấy mình sẽ làm các task như sắp xếp lại một mô hình dữ liệu vào một ngày nào đó, xây dựng một công cụ gắn nhãn dữ liệu, tối ưu hóa framework học sâu nội bộ. Các kỹ sư dữ liệu giỏi rất linh hoạt, ham học hỏi và sẵn sàng thử những điều mới.
Kết luận
Trên đây là phần giới thiệu về lĩnh vực kỹ thuật dữ liệu, một trong những ngành được yêu cầu nhiều nhất đối với những người có kiến thức nền tảng hoặc quan tâm đến khoa học máy tính và công nghệ!
Trong hướng dẫn này, bạn đã học được:
- Kỹ sư dữ liệu làm gì
- Khách hàng của kỹ sư dữ liệu là ai
- Những kỹ năng nào phổ biến đối với kỹ thuật dữ liệu
- Những gì không phải là Kỹ thuật dữ liệu.
Nguyễn Hải Nam
Dịch từ bài viết What Is Data Engineering and Is It Right for You?
Bài liên quan
Bài liên quan
Vibe Coding Workflow: Từ Yêu Cầu Đến Code, Test Và Tài Liệu Với Sự Hỗ Trợ Của AI
Vì sao biết dùng ChatGPT chưa đủ để làm việc với AI trong lập trình?

So sánh Cursor và GitHub Copilot: Nên dùng công cụ nào cho lập trình với AI?

Vibe Coding Là Gì? Cách Lập Trình Viên Làm Việc Với AI Hiệu Quả Trong Kỷ Nguyên Mới
AI đang thay đổi công việc lập trình viên như thế nào?

AI Debug và AI Test: Lập trình viên nên tin AI đến mức nào?

Cách dùng AI để đọc hiểu codebase nhanh hơn cho developer và QA

Khóa học Vibe Coding: Xu hướng lập trình bắt buộc để không bị AI đào thải
Đăng ký nhận bản tin




Bình luận (0
)