Tìm hiểu về machine learning
Bài viết này sẽ giúp các bạn tìm hiểu về machine learing bằng việc cung cấp một cái nhìn tổng quan về lịch sử, các định nghĩa quan trọng, các ứng dụng và mối quan tâm về học máy trong các doanh nghiệp ngày nay.
Machine learning (Học máy) là gì – Tìm hiểu về machine learning
Machine learning là một nhánh của trí tuệ nhân tạo (AI) và khoa học máy tính, tập trung vào việc sử dụng dữ liệu và thuật toán để bắt chước cách con người học, dần dần cải thiện độ chính xác của nó.
IBM có một lịch sử phong phú về học máy. Một trong những người chủ của nó, Arthur Samuel đã đặt ra thuật ngữ “machine learning” với nghiên cứu của ông (PDF, 481 KB) (liên kết bên ngoài IBM) xung quanh trò chơi cờ caro. Robert Nealey, một bậc thầy cờ caro tự xưng đã chơi trò chơi này trên máy tính IBM 7094 vào năm 1962, và ông đã thua chiếc máy tính này. So với những gì có thể làm được ngày nay thì kỳ tích này gần như không đáng kể, nhưng nó được coi là một cột mốc quan trọng trong lĩnh vực AI. Trong vài thập kỷ tới, các phát triển công nghệ xung quanh khả năng lưu trữ và xử lý sẽ tạo điều kiện cho một số sản phẩm sáng tạo mà chúng ta biết và yêu thích ngày nay, chẳng hạn như công cụ đề xuất của Netflix hoặc ô tô tự lái.

Machine learning là một thành phần quan trọng của lĩnh vực khoa học dữ liệu hiện đang phát triển. Thông qua việc sử dụng các phương pháp thống kê, các thuật toán được huấn luyện để đưa ra phân loại hoặc dự đoán, khám phá các hiểu biết quan trọng trong các dự án khai phá dữ liệu. Những kiến thức này sẽ thúc đẩy việc đưa ra quyết định trong các ứng dụng và doanh nghiệp, tác động lý tưởng đến các chỉ số tăng trưởng chính. Khi dữ liệu lớn (big data) tiếp tục mở rộng và phát triển, nhu cầu thị trường đối với các nhà khoa học dữ liệu sẽ tăng lên, đòi hỏi họ cần hỗ trợ xác định các câu hỏi kinh doanh phù hợp nhất rồi đến dữ liệu để trả lời chúng.
Machine Learning với Deep Learning với Mạng Nơ-ron
Vì deep learning (học sâu) và machine learning (học máy) có xu hướng được sử dụng thay thế cho nhau, nên cần lưu ý các sắc thái giữa hai lĩnh vực này. Machine learning, deep learning và mạng nơ-ron đều là các lĩnh vực phụ của AI. Tuy nhiên, thực ra deep learning là một lĩnh vực phụ của machine learning và mạng nơ-ron là một lĩnh vực phụ của deep learning.
Deep learning và machine learning khác nhau ở cách học của mỗi thuật toán. Deep learning tự động hóa phần lớn phần trích xuất đặc trưng của quy trình, loại bỏ một số can thiệp thủ công của con người và cho phép sử dụng các tập dữ liệu lớn hơn. Bạn có thể coi deep learning là “machine learning mở rộng” như Lex Fridman đã lưu ý trong bài giảng MIT (01:08:05). Machine learning cổ điển, hoặc “không sâu” phụ thuộc nhiều hơn vào sự can thiệp của con người để học. Các chuyên gia về con người xác định tập hợp các đặc trưng để hiểu sự khác biệt giữa các đầu vào dữ liệu, thường yêu cầu nhiều dữ liệu có cấu trúc hơn để tìm hiểu.
Học máy “sâu” có thể tận dụng tập dữ liệu được gắn nhãn, còn được gọi là học có giám sát (supervised learning), để thông báo cho thuật toán của nó, nhưng không nhất thiết phải yêu cầu tập dữ liệu được gắn nhãn. Nó có thể nhập dữ liệu phi cấu trúc ở dạng thô (ví dụ: văn bản, hình ảnh) và nó có thể tự động xác định tập hợp các tính năng giúp phân biệt các danh mục dữ liệu khác nhau với nhau. Không giống như machine learning, nó không yêu cầu sự can thiệp của con người để xử lý dữ liệu, cho phép chúng ta mở rộng quy mô học máy theo những cách thú vị hơn. Deep learning và mạng nơ-ron chủ yếu được ghi nhận là giúp tăng tốc tiến bộ trong các lĩnh vực, chẳng hạn như thị giác máy tính (computer vision), xử lý ngôn ngữ tự nhiên (natural language processing) và nhận dạng giọng nói (speech recognition).
Mạng nơ-ron, hay mạng nơ-ron nhân tạo (ANN), bao gồm các lớp node, chứa một lớp đầu vào, một hoặc nhiều lớp ẩn và một lớp đầu ra. Mỗi node, hoặc nơ-ron nhân tạo, kết nối với một node khác và có trọng số và ngưỡng liên quan. Nếu đầu ra của bất kỳ node riêng lẻ nào vượt quá giá trị ngưỡng được chỉ định, node đó sẽ được kích hoạt, gửi dữ liệu đến lớp tiếp theo của mạng. Nếu không, không có dữ liệu nào được chuyển đến lớp tiếp theo của mạng. Từ “deep” trong deep learning chỉ là đề cập đến độ sâu của các lớp trong mạng nơ-ron. Một mạng nơ-ron bao gồm hơn ba lớp — sẽ bao gồm các lớp đầu vào và lớp đầu ra — có thể được coi là một thuật toán deep learning hoặc mạng nơ-ron sâu. Một mạng nơ-ron chỉ có hai hoặc ba lớp chỉ là một mạng nơ-ron cơ bản.
Machine learning hoạt động như thế nào?
UC Berkeley chia hệ thống học tập của một thuật toán học máy thành ba phần chính.
- Quy trình quyết định: Nói chung, các thuật toán học máy được sử dụng để đưa ra dự đoán hoặc phân loại. Dựa trên một số dữ liệu đầu vào, có thể được gắn nhãn hoặc không được gắn nhãn, thuật toán của bạn sẽ đưa ra ước tính về một mẫu trong dữ liệu.
- Hàm lỗi: Một hàm lỗi dùng để đánh giá dự đoán của mô hình. Nếu có các ví dụ đã biết, một hàm lỗi có thể thực hiện so sánh để đánh giá độ chính xác của mô hình.
- Quy trình tối ưu hóa mô hình: Nếu mô hình có thể phù hợp hơn với các điểm dữ liệu trong tập huấn luyện (training set), thì trọng số được điều chỉnh để giảm sự khác biệt giữa ví dụ đã biết và ước tính mô hình. Thuật toán sẽ lặp lại quá trình đánh giá và tối ưu hóa này, cập nhật trọng số một cách tự động cho đến khi đạt đến ngưỡng chính xác.
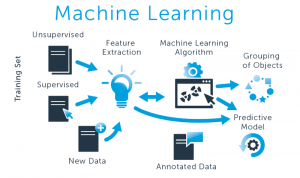
Các phương thức học máy
Học máy được chia thành 3 loại chính
- Học có giám sát
Học có giám sát, còn được gọi là học máy có giám sát, được định nghĩa bằng cách sử dụng các tập dữ liệu được gắn nhãn để huấn luyện các thuật toán nhằm phân loại dữ liệu hoặc dự đoán kết quả một cách chính xác. Khi dữ liệu đầu vào được đưa vào mô hình, nó sẽ điều chỉnh trọng số của nó cho đến khi mô hình được lắp một cách thích hợp. Đây là một phần của quá trình xác nhận chéo để đảm bảo rằng mô hình tránh trang bị overfitting hoặc underfitting. Học tập có giám sát giúp các tổ chức giải quyết nhiều vấn đề trong thế giới thực trên quy mô lớn, chẳng hạn như phân loại thư rác trong một thư mục riêng biệt từ hộp thư đến của bạn. Một số phương thức được sử dụng trong học có giám sát bao gồm mạng nơ-ron, naïve bayes, hồi quy tuyến tính, hồi quy logistic, random forest, máy vectơ hỗ trợ (SVM), …
2. Học không giám sát
Học không giám sát, còn được gọi là học máy không giám sát, sử dụng các thuật toán học máy để phân tích và phân cụm các tập dữ liệu không được gắn nhãn. Các thuật toán này phát hiện ra các mẫu hoặc nhóm dữ liệu ẩn mà không cần sự can thiệp của con người. Khả năng phát hiện ra những điểm tương đồng và khác biệt trong thông tin khiến nó trở thành giải pháp lý tưởng để phân tích dữ liệu khám phá, chiến lược bán chéo, phân khúc khách hàng, nhận dạng hình ảnh và mẫu. Nó cũng được sử dụng để giảm số lượng tính năng trong một mô hình thông qua quá trình giảm kích thước; phân tích thành phần chính (PCA) và phân tích giá trị đơn lẻ (SVD) là hai cách tiếp cận phổ biến cho việc này. Các thuật toán khác được sử dụng trong học tập không giám sát bao gồm mạng nơ-ron, phân cụm k-mean, phương pháp phân nhóm xác suất, v.v.
3. Học bán giám sát
Học bán giám sát cung cấp một phương tiện trung gian giữa học tập có giám sát và không giám sát. Trong quá trình huấn luyện, nó sử dụng một tập dữ liệu có nhãn nhỏ hơn để hướng dẫn phân loại và trích xuất tính năng từ một tập dữ liệu lớn hơn, không được gắn nhãn. Học bán giám sát có thể giải quyết vấn đề không có đủ dữ liệu được gắn nhãn (hoặc không đủ khả năng gắn nhãn đủ dữ liệu) để huấn luyện thuật toán học có giám sát.
Để tìm hiểu sâu hơn về sự khác biệt giữa các phương pháp này, hãy xem “Học tập có giám sát và không giám sát: Sự khác biệt là gì?“
Học máy tăng cường
Reinforcement machine learning là một mô hình học máy hành vi tương tự như học có giám sát, nhưng thuật toán không được huấn luyện bằng cách sử dụng dữ liệu mẫu. Mô hình này sẽ học theo cách sử dụng thử (trail) và sai (error). Một chuỗi các kết quả thành công sẽ được củng cố để phát triển khuyến nghị hoặc chính sách tốt nhất cho một vấn đề nhất định.
Hệ thống IBM Watson® đã giành chiến thắng trong cuộc thi Jeopardy! challenge trong năm 2011 là một ví dụ điển hình. Hệ thống đã sử dụng phương pháp học tăng cường để quyết định xem có nên thử trả lời (hoặc câu hỏi) hay không, chọn ô vuông nào trên bàn cờ và đặt cược bao nhiêu – đặc biệt là đối với các trận đấu đôi hàng ngày.
Các trường hợp sử dụng học máy trong thế giới thực

Dưới đây là một vài ví dụ về học máy mà bạn có thể gặp hàng ngày:
Nhận dạng giọng nói: Nó còn được gọi là nhận dạng giọng nói tự động (ASR), nhận dạng giọng nói máy tính hoặc chuyển giọng nói thành văn bản và nó là một khả năng sử dụng xử lý ngôn ngữ tự nhiên (NLP) để xử lý giọng nói của con người thành định dạng viết. Nhiều thiết bị di động tích hợp tính năng nhận dạng giọng nói vào hệ thống để thực hiện tìm kiếm bằng giọng nói — ví dụ như Siri — hoặc cung cấp nhiều khả năng tiếp cận hơn đối với việc nhắn tin.
Dịch vụ khách hàng: Chatbots trực tuyến đang thay thế các tác nhân con người trong hành trình của khách hàng. Chúng trả lời các câu hỏi thường gặp (FAQ) xung quanh các chủ đề, như vận chuyển hoặc cung cấp lời khuyên được cá nhân hóa, bán sản phẩm chéo hoặc đề xuất kích thước cho người dùng, thay đổi cách chúng ta nghĩ về mức độ tương tác của khách hàng trên các trang web và nền tảng truyền thông xã hội. Ví dụ bao gồm bot nhắn tin trên các trang web thương mại điện tử với tác nhân ảo, ứng dụng nhắn tin, chẳng hạn như Slack và Facebook Messenger, và các tác vụ thường được thực hiện bởi trợ lý ảo và trợ lý giọng nói.
Thị giác máy tính: Công nghệ AI này cho phép máy tính và hệ thống lấy thông tin có ý nghĩa từ hình ảnh kỹ thuật số, video và các đầu vào trực quan khác và dựa trên các đầu vào đó, nó có thể thực hiện hành động. Khả năng cung cấp các khuyến nghị này chính là điểm khác biệt so với các tác vụ nhận dạng hình ảnh. Được hỗ trợ bởi mạng nơ-ron phức hợp, thị giác máy tính có các ứng dụng trong việc gắn thẻ ảnh trên mạng xã hội, chụp ảnh X quang trong y tế và xe hơi tự lái trong ngành công nghiệp ô tô.
Công cụ đề xuất: Sử dụng dữ liệu hành vi tiêu dùng trong quá khứ, các thuật toán AI có thể giúp khám phá các xu hướng dữ liệu có thể được sử dụng để phát triển các chiến lược bán chéo hiệu quả hơn. Chúng còn được sử dụng để đưa ra các đề xuất bổ sung có liên quan cho khách hàng trong quá trình thanh toán cho các nhà bán lẻ trực tuyến.
Giao dịch chứng khoán tự động: Được thiết kế để tối ưu hóa danh mục đầu tư chứng khoán, các nền tảng giao dịch tần suất cao do AI điều khiển thực hiện hàng nghìn hoặc thậm chí hàng triệu giao dịch mỗi ngày mà không cần sự can thiệp của con người.
Các thách thức của học máy
Khi công nghệ học máy tiến bộ, nó chắc chắn đã làm cho cuộc sống của chúng ta dễ dàng hơn. Tuy nhiên, việc triển khai học máy trong các doanh nghiệp cũng làm dấy lên một số lo ngại về đạo đức xung quanh các công nghệ AI. Một vài trong số này bao gồm:
Điểm phi thường về công nghệ
Trong khi chủ đề này thu hút được nhiều sự chú ý của công chúng, nhiều nhà nghiên cứu không mấy quan tâm đến ý tưởng AI sẽ vượt qua trí thông minh của con người trong tương lai gần hay trước mắt. Đây còn được gọi là trí tuệ siêu việt, được Nick Bostrum định nghĩa là “bất kỳ trí tuệ nào vượt trội hơn hẳn những bộ não tốt nhất của con người trong thực tế mọi lĩnh vực, bao gồm óc sáng tạo khoa học, trí tuệ nói chung và kỹ năng xã hội”. Mặc dù thực tế là AI mạnh và trí tuệ siêu việt sẽ không xảy ra trong tương lai gần trong xã hội, nhưng ý tưởng về vẫn đề này vẫn đặt ra một số câu hỏi thú vị khi chúng ta xem xét việc sử dụng các hệ thống tự hành, như ô tô tự lái. Thật không thực tế khi nghĩ rằng một chiếc ô tô không người lái sẽ không bao giờ gặp tai nạn ô tô, nhưng ai là người chịu trách nhiệm trong những trường hợp đó? Liệu chúng ta có nên theo đuổi phương tiện tự hành hay chúng ta hạn chế việc tích hợp công nghệ này để chỉ tạo ra các phương tiện bán tự hành giúp tăng cường sự an toàn cho người lái xe? Ban giám khảo vẫn chưa có ý kiến về vấn đề này, nhưng đây là những tranh luận về đạo đức đang diễn ra khi công nghệ AI mới, sáng tạo phát triển.
Tác động của AI đối với nghề nghiệp
Trong khi công chúng rất quan tâm đến các trung tâm trí tuệ nhân tạo về vấn đề mất việc làm, mối quan tâm này có lẽ nên được loại bỏ. Với mỗi công nghệ mới, đột phá, chúng ta thấy rằng nhu cầu thị trường về các vai trò công việc cụ thể sẽ thay đổi. Ví dụ, khi chúng ta nhìn vào ngành công nghiệp ô tô, nhiều nhà sản xuất, như GM, đang chuyển sang tập trung vào sản xuất xe điện để phù hợp với các sáng kiến xanh. Ngành năng lượng sẽ không biến mất, nhưng nguồn năng lượng đang chuyển từ nền kinh tế nhiên liệu sang điện. Trí tuệ nhân tạo cũng nên được nhìn nhận theo cách tương tự, trong đó trí tuệ nhân tạo sẽ chuyển nhu cầu việc làm sang các lĩnh vực khác. Sẽ cần có những cá nhân giúp quản lý các hệ thống này khi dữ liệu phát triển và thay đổi hàng ngày. Sẽ vẫn cần có các nguồn lực để giải quyết các vấn đề phức tạp hơn trong các ngành có nhiều khả năng bị ảnh hưởng bởi sự thay đổi nhu cầu công việc, chẳng hạn như dịch vụ khách hàng. Khía cạnh quan trọng của trí tuệ nhân tạo và tác động của nó đối với thị trường việc làm sẽ giúp các cá nhân chuyển đổi sang các lĩnh vực mới của nhu cầu thị trường.
Quyền riêng tư
Quyền riêng tư thường được thảo luận trong bối cảnh bảo mật dữ liệu, bảo vệ dữ liệu và bảo mật dữ liệu, và những lo ngại này đã cho phép các nhà hoạch định chính sách đạt được nhiều bước tiến hơn trong những năm gần đây. Ví dụ: vào năm 2016, luật GDPR được tạo ra để bảo vệ dữ liệu cá nhân của những người ở Liên minh châu Âu và Khu vực kinh tế châu Âu, giúp các cá nhân có khả năng kiểm soát dữ liệu cao hơn. Tại Hoa Kỳ, các bang riêng lẻ đang phát triển các chính sách, chẳng hạn như Đạo luật Quyền riêng tư của Người tiêu dùng California (CCPA), yêu cầu các doanh nghiệp thông báo cho người tiêu dùng về việc thu thập dữ liệu của họ. Đạo luật gần đây này đã buộc các công ty phải suy nghĩ lại về cách họ lưu trữ và sử dụng dữ liệu nhận dạng cá nhân (PII). Do đó, các khoản đầu tư vào bảo mật ngày càng trở thành ưu tiên hàng đầu của các doanh nghiệp khi họ tìm cách loại bỏ mọi lỗ hổng và cơ hội cho việc giám sát, hack và tấn công mạng.
Thiên vị và phân biệt đối xử
Các trường hợp thiên vị và phân biệt đối xử trên một số hệ thống thông minh đã đặt ra nhiều câu hỏi về đạo đức liên quan đến việc sử dụng trí tuệ nhân tạo. Làm thế nào chúng ta có thể bảo vệ chống lại sự thiên vị và phân biệt đối xử khi bản thân dữ liệu huấn luyện có thể tự cho mình sự thiên vị? Trong khi các công ty thường có ý định tốt khi nỗ lực tự động hóa, Reuters (liên kết bên ngoài IBM) nêu bật một số hậu quả không lường trước được của việc kết hợp AI vào thực tiễn tuyển dụng. Trong nỗ lực tự động hóa và đơn giản hóa quy trình, Amazon đã vô tình thiên vị các ứng viên tiềm năng theo giới tính cho các vị trí kỹ thuật mở và cuối cùng họ phải hủy bỏ dự án. Khi những sự kiện như thế này xuất hiện, Harvard Business Review (liên kết bên ngoài IBM) đã đưa ra những câu hỏi quan trọng khác xung quanh việc sử dụng AI trong các hoạt động tuyển dụng, chẳng hạn như dữ liệu nào bạn có thể sử dụng khi đánh giá ứng viên cho một vị trí.
Sự thiên vị và phân biệt đối xử cũng không chỉ giới hạn ở chức năng nguồn nhân lực; nó có thể được tìm thấy trong một số ứng dụng từ phần mềm nhận dạng khuôn mặt đến các thuật toán mạng xã hội.
Khi các doanh nghiệp nhận thức rõ hơn về những rủi ro với AI, họ cũng trở nên tích cực hơn trong cuộc thảo luận về đạo đức và giá trị của AI. Ví dụ, năm ngoái, Giám đốc điều hành của IBM, Arvind Krishna, đã chia sẻ rằng IBM đã từ bỏ mục đích chung của mình là các sản phẩm phân tích và nhận dạng khuôn mặt IBM, nhấn mạnh rằng “IBM kiên quyết phản đối và sẽ không dung thứ cho việc sử dụng bất kỳ công nghệ nào, bao gồm cả công nghệ nhận dạng khuôn mặt do các nhà cung cấp khác cung cấp cho đại chúng, giám sát, phân biệt chủng tộc, vi phạm các quyền và tự do cơ bản của con người hoặc bất kỳ mục đích nào không phù hợp với các giá trị và Nguyên tắc Tin cậy và Minh bạch của chúng tôi. ”
Để đọc thêm về vấn đề này, hãy xem blog chính sách của IBM, nêu lên quan điểm của mình về “Phương pháp tiếp cận theo quy định chính xác để kiểm soát xuất khẩu công nghệ nhận dạng khuôn mặt”.
Trách nhiệm giải trình
Vì không có luật quan trọng để điều chỉnh các hoạt động AI, nên không có cơ chế thực thi thực sự nào để đảm bảo rằng AI có đạo đức được thực thi. Các động lực hiện tại cho các công ty tuân thủ các nguyên tắc này là hậu quả tiêu cực của hệ thống AI phi đạo đức đối với điểm mấu chốt. Để lấp đầy khoảng trống, các khuôn khổ đạo đức đã xuất hiện như một phần của sự hợp tác giữa các nhà đạo đức học và các nhà nghiên cứu để quản lý việc xây dựng và phân phối các mô hình AI trong xã hội. Tuy nhiên, hiện tại, những điều này chỉ phục vụ cho mục đích hướng dẫn và nghiên cứu (liên kết bên ngoài IBM) (PDF, 1 MB) cho thấy rằng sự kết hợp giữa trách nhiệm phân tán và việc thiếu tầm nhìn xa vào những hậu quả tiềm ẩn không nhất thiết có lợi cho việc ngăn ngừa tổn hại cho xã hội.
Nguyễn Hải Nam
Dịch từ bài Machine Learning
Tìm hiểu: khoá học Machine Learning cam kết đầu ra với mức lương 12-16 triệu/tháng.
Bài liên quan
Bài liên quan
Vibe Coding Workflow: Từ Yêu Cầu Đến Code, Test Và Tài Liệu Với Sự Hỗ Trợ Của AI
Vì sao biết dùng ChatGPT chưa đủ để làm việc với AI trong lập trình?

So sánh Cursor và GitHub Copilot: Nên dùng công cụ nào cho lập trình với AI?

Vibe Coding Là Gì? Cách Lập Trình Viên Làm Việc Với AI Hiệu Quả Trong Kỷ Nguyên Mới
AI đang thay đổi công việc lập trình viên như thế nào?

AI Debug và AI Test: Lập trình viên nên tin AI đến mức nào?

Cách dùng AI để đọc hiểu codebase nhanh hơn cho developer và QA

Khóa học Vibe Coding: Xu hướng lập trình bắt buộc để không bị AI đào thải
Đăng ký nhận bản tin




Bình luận (0
)