Hướng dẫn sơ bộ về Data Science (Khoa học dữ liệu)
Khoa học dữ liệu là lĩnh vực áp dụng các kỹ thuật phân tích tiên tiến và các nguyên tắc khoa học để trích xuất thông tin có giá trị từ dữ liệu để ra quyết định kinh doanh, lập kế hoạch chiến lược và các mục đích sử dụng khác. Nó ngày càng có vị trí quan trọng đối với các doanh nghiệp: Những hiểu biết sâu sắc mà khoa học dữ liệu tạo ra giúp các tổ chức tăng hiệu suất vận hành, nhận định các cơ hội kinh doanh mới và cải thiện các chương trình tiếp thị và bán hàng cùng các lợi ích khác. Như vậy, khoa học dữ liệu giúp tìm kiếm lợi thế cạnh tranh so với các đối thủ kinh doanh khác.
Khoa học dữ liệu kết hợp nhiều lĩnh vực khác nhau – chẳng hạn như data engineering (kỹ thuật dữ liệu), data preparation (chuẩn bị dữ liệu), data mining (khai phá dữ liệu), predictive analytics (phân tích dự đoán), machine learning (học máy) và data visualization (trực quan hóa dữ liệu) cũng như thống kê, toán học và lập trình phần mềm. Ngành này chủ yếu gồm các nhà khoa học dữ liệu lành nghề, cũng có cả các nhà phân tích dữ liệu cấp thấp hơn. Ngoài ra, nhiều tổ chức hiện nay phụ thuộc một phần vào các nhà khoa học dữ liệu công dân (citizen data scientist), đó là một nhóm gồm các chuyên gia kinh doanh thông minh (BI), nhà phân tích kinh doanh, người dùng doanh nghiệp am hiểu dữ liệu, kỹ sư dữ liệu và những người lao động khác không có nền tảng khoa học dữ liệu chính thức.
Hướng dẫn toàn diện về khoa học dữ liệu này sẽ giúp giải thích thêm về khái niệm, tầm quan trọng của nó đối với các tổ chức, cách thức hoạt động, lợi ích kinh doanh mà nó cung cấp và những thách thức mà nó đặt ra. Chúng ta cũng sẽ tìm hiểu tổng quan về các ứng dụng, công cụ và kỹ thuật khoa học dữ liệu, cùng với thông tin về những việc mà các nhà khoa học dữ liệu thực hiện và các kỹ năng họ cần. Trong suốt hướng dẫn sẽ có các liên kết đến các bài báo của TechTarget có liên quan để tìm hiểu sâu hơn về các chủ đề được đề cập ở đây và cung cấp thông tin chi tiết cũng như lời khuyên của chuyên gia về các sáng kiến khoa học dữ liệu.
1. Tại sao khoa học dữ liệu lại quan trọng đến vậy?
Khoa học dữ liệu đóng vai trò quan trọng trong hầu hết các khía cạnh của hoạt động và chiến lược kinh doanh. Ví dụ: nó cung cấp thông tin về khách hàng, giúp công ty đưa ra các chiến dịch tiếp thị mạnh mẽ hơn và quảng cáo nhắm mục tiêu để tăng doanh số bán hàng. Nó hỗ trợ việc quản lý rủi ro tài chính, phát hiện giao dịch gian lận và ngăn ngừa sự cố thiết bị trong các nhà máy sản xuất và các cơ sở công nghiệp khác. Nó cũng giúp ngăn chặn các cuộc tấn công mạng và các mối đe dọa bảo mật khác trong hệ thống CNTT.
góc nhìn vận hành, các sáng kiến khoa học dữ liệu giúp tối ưu hóa việc quản lý chuỗi cung ứng, hàng tồn kho, mạng lưới phân phối và dịch vụ khách hàng. Ở cấp độ cơ bản hơn, khoa học dữ liệu chỉ ra cách tăng hiệu suất và giảm chi phí. Khoa học dữ liệu cũng cho phép các công ty tạo ra các kế hoạch và chiến lược kinh doanh dựa trên phân tích thông tin về hành vi của khách hàng, xu hướng thị trường và cạnh tranh. Nếu không có nó, doanh nghiệp có thể sẽ bỏ lỡ cơ hội và đưa ra các quyết định sai lầm.
Khoa học dữ liệu cũng rất quan trọng trong các lĩnh vực khác ngoài hoạt động kinh doanh thông thường. Trong chăm sóc sức khỏe, nó có công dụng trong việc chẩn đoán tình trạng y tế, phân tích hình ảnh, lập kế hoạch điều trị và nghiên cứu y học. Các tổ chức học thuật sử dụng khoa học dữ liệu để theo dõi kết quả hoạt động của sinh viên và cải thiện hoạt động tiếp thị của họ tới các sinh viên tương lai. Các đội thể thao phân tích hiệu suất của người chơi và lập kế hoạch chiến lược trò chơi thông qua khoa học dữ liệu. Các cơ quan chính phủ và các tổ chức chính sách công cũng sử dụng khá nhiều khoa học dữ liệu.
2. Quy trình và vòng đời của khoa học dữ liệu
Các dự án khoa học dữ liệu gồm nhiều bước thu thập và phân tích dữ liệu. Trong tài liệu mô tả quy trình khoa học dữ liệu, Donald Farmer – chủ của của công ty tư vấn phân tích TreeHive Strategy đã nêu ra sáu bước chính sau:
- Xác định một giả thuyết liên quan đến kinh doanh để kiểm tra.
- Thu thập và chuẩn bị dữ liệu để phân tích.
- Thử nghiệm với các mô hình phân tích khác nhau.
- Chọn mô hình tốt nhất và chạy với dữ liệu.
- bày kết quả với các nhà quản trị doanh nghiệp.
- Triển khai mô hình để sử dụng liên tục với dữ liệu mới.
Farmer cho biết quá trình này biến khoa học dữ liệu trở thành một nỗ lực khoa học. Tuy nhiên, ông cho rằng, ở các doanh nghiệp, công việc khoa học dữ liệu “sẽ luôn tập trung một cách hữu ích nhất vào các thực tế thương mại đơn giản” có thể mang lại lợi ích cho doanh nghiệp. Do đó, ông cho rằng các nhà khoa học dữ liệu nên hợp tác với các bên liên quan của doanh nghiệp trong suốt các dự án về vòng đời của phân tích.
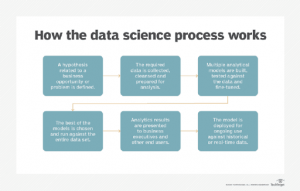
Quy trình khoa học dữ liệu bao gồm sáu bước sau.
3. Lợi ích của khoa học dữ liệu
Trong một cuộc hội thảo web vào tháng 10 năm 2020 do Viện Khoa học Tính toán Ứng dụng của Đại học Harvard tổ chức, Jessica Stauth – giám đốc điều hành khoa học dữ liệu của đơn vị Fidelity Labs tại Fidelity Investments cho biết có “mối quan hệ rất rõ ràng” giữa công việc khoa học dữ liệu và kết quả kinh doanh. Jessica trích dẫn những lợi ích kinh doanh tiềm năng bao gồm ROI cao hơn, tăng trưởng doanh số, hoạt động hiệu quả hơn, thời gian tiếp thị nhanh hơn, tăng mức độ tương tác và sự hài lòng của khách hàng cũng tăng lên.
Nhìn chung, một trong những lợi ích lớn nhất của khoa học dữ liệu là trao quyền và tạo điều kiện cho việc ra những quyết định tốt hơn. Các tổ chức đầu tư vào nó có thể biến bằng chứng dựa trên dữ liệu định lượng thành các quyết định kinh doanh. Lý tưởng nhất là các quyết định dựa trên dữ liệu như vậy sẽ dẫn đến hiệu suất kinh doanh mạnh mẽ hơn, tiết kiệm chi phí và có quy trình kinh doanh trơn tru hơn.
Các lợi ích kinh doanh cụ thể của khoa học dữ liệu sẽ khác nhau tùy thuộc vào công ty và ngành nghề. Ví dụ: trong các tổ chức phải đối mặt với khách hàng, khoa học dữ liệu giúp xác định và tinh chỉnh đối tượng mục tiêu. Các bộ phận tiếp thị và bán hàng có thể khai thác dữ liệu khách hàng để cải thiện tỷ lệ chuyển đổi và tạo các chiến dịch tiếp thị và khuyến mại được cá nhân hóa, đem lại doanh số bán hàng cao hơn.
Trong các trường hợp khác, khoa học dữ liệu giúp giảm gian lận, quản lý rủi ro hiệu quả hơn, giao dịch tài chính có lợi hơn, tăng thời gian hoạt động sản xuất, hiệu suất chuỗi cung ứng tốt hơn, bảo vệ an ninh mạng mạnh mẽ hơn và cải thiện kết quả của bệnh nhân. Khoa học dữ liệu cũng cho phép phân tích dữ liệu theo thời gian thực khi dữ liệu được tạo ra – hãy đọc thêm về những lợi ích mà phân tích thời gian thực mang lại, bao gồm việc đưa ra quyết định nhanh hơn và tăng tính nhạy bén trong kinh doanh.
4. Ứng dụng của khoa học dữ liệu và các trường hợp sử dụng
Các ứng dụng phổ biến mà các nhà khoa học dữ liệu tham gia gồm mô hình dự đoán, nhận dạng mẫu, phát hiện bất thường, phân loại, phân loại và phân tích cảm xúc, phát triển các công nghệ như công cụ đề xuất, hệ thống cá nhân hóa và các công cụ trí tuệ nhân tạo (AI) như chatbot, xe tự lái và các loại máy móc.
Các ứng dụng đó thúc đẩy nhiều trường hợp sử dụng khác nhau trong các tổ chức, bao gồm:
- phân tích khách hàng
- phát hiện gian lận
- quản lý rủi ro
- giao dịch chứng khoán
- quảng cáo nhắm mục tiêu
- cá nhân hóa trang web
- dịch vụ khách hàng
- bảo trì dự đoán
- quản lý chuỗi cung ứng và logistics
- nhận dạng hình ảnh
- nhận dạng giọng nói
- xử lý ngôn ngữ tự nhiên
- an ninh mạng
- chẩn đoán y tế
Hãy tìm hiểu thêm về tám ứng dụng khoa học dữ liệu hàng đầu và các trường hợp sử dụng liên quan trong bài viết của Ronald Schmelzer, nhà phân tích chính và đối tác quản lý tại Cognilytica, một công ty nghiên cứu và tư vấn tập trung vào AI.
5. Những thách thức của khoa học dữ liệu
Khoa học dữ liệu vốn có nhiều thách thức do bản chất cấp tiến của phân tích. Lượng lớn dữ liệu thường được lấy để phân tích làm gia tăng độ phức tạp và tăng thời gian hoàn thành dự án. Ngoài ra, các nhà khoa học dữ liệu thường xuyên làm việc với các nhóm dữ liệu lớn có thể chứa nhiều loại dữ liệu có cấu trúc, phi cấu trúc và bán cấu trúc, làm phức tạp thêm quá trình phân tích.

Những trở ngại này là một trong những thách thức mà các nhóm khoa học dữ liệu phải đối mặt.
Một trong những thách thức lớn nhất là loại bỏ sự độ chệch trong các tập dữ liệu và ứng dụng phân tích. Điều đó gồm các vấn đề với chính bản thân dữ liệu và những vấn đề mà các nhà khoa học dữ liệu vô thức xây dựng thành các thuật toán và mô hình dự đoán. Nếu không được phát hiện và giải quyết, những độ chệch như vậy có thể làm sai lệch kết quả phân tích, tạo ra những phát hiện thiếu sót dẫn đến các quyết định kinh doanh sai lầm. Thậm chí tệ hơn, chúng có thể gây ra những tác động có hại đối với các nhóm người – ví dụ: trường hợp thiên vị chủng tộc trong các hệ thống AI.
Việc tìm kiếm dữ liệu phù hợp để phân tích lại là một thách thức khác. Trong một báo cáo được công bố vào tháng 1 năm 2020, phân tích viên Afraz Jaffri của Gartner và bốn cộng sự của ông tại công ty tư vấn cũng cho rằng việc lựa chọn các công cụ phù hợp, quản lý triển khai các mô hình phân tích, định lượng giá trị kinh doanh và duy trì các mô hình là những rào cản đáng kể.
Hãy đọc thêm về bốn phương pháp hay nhất cho các dự án khoa học dữ liệu trong bài viết của Yujun Chen và Dawn Li, hai nhà khoa học dữ liệu tại công ty dịch vụ phát triển phần mềm Finastra để giúp khắc phục những thách thức này.
6. Các nhà khoa học dữ liệu sẽ làm những gì? Họ cần những kỹ năng nào?
Vai trò chính của các nhà khoa học dữ liệu là phân tích dữ liệu, thường là với lượng lớn dữ liệu để nỗ lực tìm kiếm thông tin hữu ích có thể chia sẻ với các giám đốc điều hành doanh nghiệp, quản lý doanh nghiệp và người lao động, cũng như các quan chức chính phủ, bác sĩ, nhà nghiên cứu,… Các nhà khoa học dữ liệu cũng tạo ra các công cụ và công nghệ AI để triển khai trong nhiều ứng dụng khác nhau. Dù trong trường hợp nào, nhiệm vụ của họ là thu thập dữ liệu, phát triển các mô hình phân tích, sau đó huấn luyện, kiểm tra và chạy các mô hình dựa trên dữ liệu.
Do đó, các nhà khoa học dữ liệu phải kết hợp giữa việc chuẩn bị dữ liệu, khai phá dữ liệu, mô hình dự đoán, học máy, phân tích thống kê và kỹ năng toán học, cũng như kinh nghiệm với các thuật toán và mã hóa – chẳng hạn: kỹ năng lập trình bằng các ngôn ngữ như Python, R và SQL. Nhiều người cũng được giao nhiệm vụ tạo trực quan hóa dữ liệu, dashboard và báo cáo để minh họa các kết quả phân tích.

Các nhà khoa học dữ liệu cần nhiều phẩm chất cá nhân và chuyên nghiệp.
Ngoài những kỹ năng chuyên môn đó, nhà khoa học dữ liệu cũng cần có các kỹ năng mềm, bao gồm kiến thức kinh doanh, tính tò mò và tư duy phản biện. Một kỹ năng quan trọng khác là khả năng trình bày thông tin chi tiết về dữ liệu và giải thích ý nghĩa của chúng sao cho người dùng doanh nghiệp hiểu được. Điều đó bao gồm khả năng kể chuyện dữ liệu (data storytelling) để kết hợp trực quan hóa dữ liệu và văn bản tường thuật trong một bản trình bày đã chuẩn bị kỹ lưỡng.
Hãy tìm hiểu chi tiết thêm về các kỹ năng khoa học dữ liệu cần có trong bài viết của Kathleen Walch, chuyên viên phân tích chính và đối tác quản lý khác tại Cognilytica.
7. Nhóm khoa học dữ liệu
Nhiều tổ chức đã thành lập một nhóm riêng biệt hoặc nhiều nhóm để xử lý các hoạt động khoa học dữ liệu. Trong một bài viết giải thích về cách thành lập một nhóm khoa học dữ liệu, Mary K. Pratt cho rằng nhóm khoa học dữ liệu sẽ hoạt động hiệu quả hơn là chỉ có các nhà khoa học dữ liệu. Nhóm này cũng gồm các vị trí sau:
- Kỹ sư dữ liệu. Nhiệm vụ của kỹ sư dữ liệu là thiết lập data pipelinevà hỗ trợ chuẩn bị dữ liệu và triển khai mô hình, hợp tác chặt chẽ với các nhà khoa học dữ liệu.
- Chuyên viên phân tích dữ liệu. Đây là vị trí ở cấp bậc thấp hơn dành cho các chuyên gia phân tích, những người không có kinh nghiệm hoặc kỹ năng nâng cao như các nhà khoa học dữ liệu.
- Kỹ sư học máy. Công việc theo định hướng lập trình này liên quan đến việc phát triển các mô hình học máy cần thiết cho các ứng dụng khoa học dữ liệu.
- Lập trình viên trực quan hóa dữ liệu. Vị trí này làm việc với các nhà khoa học dữ liệu để tạo trực quan hóa và dashboard được dùng để trình bày kết quả phân tích với người dùng doanh nghiệp.
- Data translator (Phiên dịch dữ liệu). Còn được gọi là phiên dịch phân tích, đó là một vị trí mới xuất hiện, là người liên lạc với các đơn vị kinh doanh, giúp lập kế hoạch các dự án và truyền đạt kết quả.
- Kiến trúc sư dữ liệu. Kiến trúc sư dữ liệu là người thiết kế và giám sát việc triển khai các hệ thống cơ bản được sử dụng để lưu trữ và quản lý dữ liệu cho mục đích phân tích.
Nhóm như vậy thường được quản lý bởi giám đốc khoa học dữ liệu, quản lý khoa học dữ liệu hoặc nhà khoa học dữ liệu đứng đầu, người này có thể báo cáo cho giám đốc dữ liệu, giám đốc phân tích hoặc phó chủ tịch phân tích; chief data scientist là một vị trí quản lý khác mới xuất hiện trong một số tổ chức. Một số nhóm khoa học dữ liệu tập trung ở cấp độ doanh nghiệp, trong khi những nhóm khác thì phân cấp ở các đơn vị kinh doanh riêng lẻ hoặc có cấu trúc kết hợp kết hợp hai cách tiếp cận đó.
8. Business intelligence với data science
Giống như khoa học dữ liệu, trí tuệ doanh nghiệp và báo cáo cơ bản có mục đích giúp hướng dẫn việc ra quyết định vận hành và lập kế hoạch chiến lược. Nhưng BI chủ yếu tập trung vào phân tích mô tả: Điều gì đã hoặc đang xảy ra mà giờ tổ chức cần phản hồi hoặc giải quyết? Các nhà phân tích BI và người dùng BI tự phục vụ chủ yếu làm việc với dữ liệu giao dịch có cấu trúc được trích xuất từ các hệ thống vận hành, được làm sạch và biến đổi để làm cho nó nhất quán và được tải vào data warehouse hoặc data mart để phân tích. Giám sát hoạt động kinh doanh, quy trình và xu hướng là một trường hợp sử dụng BI phổ biến.
Khoa học dữ liệu liên quan đến các ứng dụng phân tích tiên tiến hơn. Ngoài phân tích mô tả, nó còn gồm phân tích dự đoán giúp dự báo hành vi và sự kiện trong tương lai, cũng như phân tích mô tả giúp tìm cách xác định phương hướng tốt nhất đối với vấn đề đang được phân tích.
Các loại dữ liệu không có cấu trúc hoặc bán cấu trúc – chẳng hạn như file nhật ký, dữ liệu cảm biến và văn bản rất phổ biến trong các ứng dụng khoa học dữ liệu cùng với dữ liệu có cấu trúc. Ngoài ra, các nhà khoa học dữ liệu thường muốn truy cập dữ liệu thô trước khi nó được làm sạch và hợp nhất để họ có thể phân tích tập dữ liệu hoặc bộ lọc đầy đủ và chuẩn bị cho các mục đích sử dụng phân tích cụ thể. Do đó, dữ liệu thô có thể lưu trữ trong data lake dựa trên Hadoop, dịch vụ lưu trữ đối tượng đám mây, cơ sở dữ liệu NoSQL hoặc một nền tảng dữ liệu lớn khác.
9. Công nghệ, kỹ thuật và phương pháp khoa học dữ liệu
Khoa học dữ liệu chủ yếu dựa vào các thuật toán học máy. Học máy là một dạng phân tích nâng cao, trong đó các thuật toán sẽ tìm hiểu về các tập dữ liệu, sau đó tìm kiếm các mẫu, điểm bất thường hoặc thông tin chi tiết về chúng. Nó sử dụng kết hợp các phương pháp học có giám sát, không giám sát, bán giám sát và tăng cường, với các thuật toán nhận có các cấp độ huấn luyện và giám sát khác nhau từ các nhà khoa học dữ liệu.
Ngoài ra còn có học sâu, một nhánh tiên tiến hơn của học máy, chủ yếu sử dụng mạng nơ-ron nhân tạo để phân tích tập hợp lớn dữ liệu không được gắn nhãn. Trong một bài viết khác, Schmelzer của Cognilytica đã giải thích mối quan hệ giữa khoa học dữ liệu, học máy và AI, nêu chi tiết các đặc điểm khác nhau của chúng và cách kết hợp chúng trong các ứng dụng phân tích.
Mô hình dự đoán là một công nghệ khoa học dữ liệu cốt lõi khác. Các nhà khoa học dữ liệu tạo ra chúng bằng cách chạy các thuật toán học máy, khai phá dữ liệu hoặc thống kê dựa trên các tập dữ liệu để dự đoán các tình huống kinh doanh và các kết quả hoặc hành vi có thể xảy ra. Trong mô hình dự đoán và các ứng dụng phân tích nâng cao khác, lấy mẫu dữ liệu thường được thực hiện để phân tích một tập hợp con dữ liệu đại diện, đây là một kỹ thuật khai phá dữ liệu giúp cho quá trình phân tích dễ quản lý hơn và ít tốn thời gian hơn.
Các kỹ thuật thống kê và phân tích phổ biến được sử dụng trong các dự án khoa học dữ liệu gồm:
- phân loại: phân tách các phần tử trong tập dữ liệu thành các hạng mục khác nhau;
- hồi quy: lập biểu đồ các giá trị tối ưu của các biến dữ liệu liên quan trong một đường thẳng hoặc mặt phẳng; và
- phân cụm: nhóm các điểm dữ liệu có mối liên hệ hoặc thuộc tính chung lại với nhau.

Ba loại kỹ thuật thống kê và phân tích được các nhà khoa học dữ liệu sử dụng nhiều nhất
10. Các công cụ và nền tảng khoa học dữ liệu
Có khá nhiều công cụ có sẵn cho các nhà khoa học dữ liệu sử dụng trong quá trình phân tích, gồm cả các tùy chọn mã nguồn mở và thương mại:
- nền tảng dữ liệu và công cụ phân tích, chẳng hạn như cơ sở dữ liệu Spark, Hadoop và NoSQL;
- ngôn ngữ lập trình, chẳng hạn như Python, R, Julia, Scala và SQL;
- các công cụ phân tích thống kê như SAS và IBM SPSS;
- các nền tảng và thư viện học máy như TensorFlow, Weka, Scikit-learning, Keras và PyTorch;
- Jupyter Notebook, một ứng dụng web giúp chia sẻ tài liệu với code, phương trình và thông tin khác; và
- các công cụ và thư viện trực quan hóa dữ liệu, chẳng hạn như Tableau, D3.js và Matplotlib.
Ngoài ra, các nhà cung cấp phần mềm cung cấp một loạt các nền tảng khoa học dữ liệu với các đặc trưng và chức năng khác nhau. Điều đó chứa các nền tảng phân tích dành cho các nhà khoa học dữ liệu có tay nghề cao, các nền tảng học máy tự động cũng có thể được dùng bởi các nhà khoa học dữ liệu công dân và các trung tâm cộng tác và quy trình làm việc cho các nhóm khoa học dữ liệu. Danh sách các nhà cung cấp bao gồm Alteryx, AWS, Databricks, Dataiku, DataRobot, Domino Data Lab, Google, H2O.ai, IBM, Knime, MathWorks, Microsoft, RapidMiner, SAS Institute, Tibco Software, …
Hãy đọc thêm về các công cụ và nền tảng khoa học dữ liệu hàng đầu trong bài viết công nghệ của Pratt.
11. Cơ hội nghề nghiệp trong ngành khoa học dữ liệu
Khi lượng dữ liệu được tạo ra và thu thập bởi các doanh nghiệp tăng lên, họ cần các nhà khoa học dữ liệu. Điều đó đã đẩy mạnh nhu cầu tuyển dụng ứng viên có kinh nghiệm hoặc được đào tạo về khoa học dữ liệu, khiến một số công ty khó có thể tìm được vị trí sẵn có.
Trong một cuộc khảo sát của Kaggle – công ty con của Google được thực hiện vào năm 2020 công ty này vận hành một cộng đồng các nhà khoa học dữ liệu trực, 51% trong số 2,675 người được hỏi đang làm công việc của một nhà khoa học dữ liệu cho biết họ có bằng thạc sĩ, 24% có bằng cử nhân và 17% có bằng tiến sĩ. Nhiều trường đại học hiện cũng cung cấp các chương trình đại học và sau đại học về khoa học dữ liệu, đây có thể là hướng đi trực tiếp để tìm việc.
Một hướng thay thế khác là đào tạo những người làm việc ở các vai trò khác thành nhà khoa học dữ liệu – đây là một lựa chọn phổ biến khi các tổ chức gặp khó khăn trong việc tìm kiếm những người có kinh nghiệm. Ngoài các chương trình học thuật, các nhà khoa học dữ liệu tiềm năng có thể tham gia các khóa đào tạo về khoa học dữ liệu và các khóa học trực tuyến trên các trang web giáo dục như Coursera và Udemy. Nhiều nhà cung cấp và nhóm ngành khác nhau cũng cung cấp các khóa học và chứng nhận về khoa học dữ liệu, các câu hỏi về khoa học dữ liệu trực tuyến cũng có thể kiểm tra và cung cấp kiến thức cơ bản.
Tính đến tháng 12 năm 2020, trang web đánh giá công ty và tìm kiếm việc làm Glassdoor đã liệt kê mức lương cơ bản trung bình của các nhà khoa học dữ liệu ở Hoa Kỳ là 113,000 USD, với mức dao động từ 83,000 USD đến 154,000 USD; mức lương trung bình cho một nhà khoa học dữ liệu cấp cao là 134,000 USD. Trên trang web việc làm Indeed, mức lương trung bình của một nhà khoa học dữ liệu là 123,000 USD cho và mức lương trung bình của một nhà khoa học dữ liệu cấp cao là 153,000 USD.
12. Các ngành phụ thuộc thế nào vào khoa học dữ liệu
Trước khi tự trở thành nhà cung cấp công nghệ, Google và Amazon đã sớm sử dụng khoa học dữ liệu và phân tích dữ liệu lớn cho các ứng dụng nội bộ cùng với các công ty thương mại điện tử và internet khác như Facebook, Yahoo và eBay. Giờ đây, khoa học dữ liệu đã phổ biến rộng rãi trong các tổ chức thuộc mọi loại hình. Dưới đây là một số ví dụ về cách sử dụng khoa học dữ liệu trong các ngành khác nhau:
- Giải trí. Khoa học dữ liệu cho phép các dịch vụ phát trực tuyến theo dõi và phân tích những gì người dùng xem, xác định các chương trình truyền hình và phim mới mà họ sản xuất. Các thuật toán theo hướng dữ liệu cũng được sử dụng để tạo các đề xuất cá nhân hóa dựa trên lịch sử xem của người dùng.
- Dịch vụ tài chính. Các ngân hàng và công ty thẻ tín dụng khai thác và phân tích dữ liệu để phát hiện các giao dịch gian lận, quản lý rủi ro tài chính đối với các khoản vay và hạn mức tín dụng, đồng thời đánh giá hồ sơ khách hàng để xác định các cơ hội bán thêm.
- Chăm sóc sức khỏe. Bệnh viện và các nhà cung cấp dịch vụ chăm sóc sức khỏe khác sử dụng mô hình học máy và các thành phần khoa học dữ liệu bổ sung để tự động hóa phân tích tia X và hỗ trợ bác sĩ chẩn đoán bệnh, lập kế hoạch điều trị dựa trên kết quả trước đó của bệnh nhân.
- Sản xuất. Khoa học dữ liệu được sử dụng để tối ưu hóa việc quản lý và phân phối chuỗi cung ứng, cộng với bảo trì dự đoán để phát hiện các lỗi thiết bị tiềm ẩn trong nhà máy trước khi chúng thực sự xảy ra.
- Bán lẻ. Các nhà bán lẻ phân tích hành vi của khách hàng và mô hình mua hàng để đưa ra các đề xuất sản phẩm và quảng cáo cá nhân hóa, tiếp thị và khuyến mại nhắm mục tiêu. Khoa học dữ liệu cũng giúp họ quản lý hàng tồn kho và chuỗi cung ứng để giữ các mặt hàng trong kho.
- Vận tải. Các công ty giao hàng, vận chuyển hàng hóa và nhà cung cấp dịch vụ hậu cần sử dụng khoa học dữ liệu để tối ưu hóa lộ trình và lịch trình giao hàng cũng như các phương thức vận tải tốt nhất cho các lô hàng.
- Du lịch. Khoa học dữ liệu hỗ trợ các hãng hàng không lập kế hoạch chuyến bay để tối ưu hóa tuyến đường, lịch trình của phi hành đoàn và tải trọng của hành khách. Các thuật toán giúp định giá cho các chuyến bay và phòng khách sạn.
Các ứng dụng khoa học dữ liệu khác trong những lĩnh vực như an ninh mạng, dịch vụ khách hàng và quản lý quy trình kinh doanh cũng khá phổ biến. Ví dụ như hỗ trợ tuyển dụng nhân viên và tìm kiếm nhân tài: Phân tích có thể xác định các đặc điểm chung của ứng viên tốt nhất, đo lường mức độ hiệu quả của các tin tuyển dụng và cung cấp thông tin khác hỗ trợ quá trình tuyển dụng.

6 ứng dụng phổ biến cho các nhà khoa học dữ liệu.
13. Lịch sử khoa học dữ liệu
Trong một bài báo xuất bản năm 1962, nhà thống kê người Mỹ John W. Tukey đã viết rằng phân tích dữ liệu “về bản chất là khoa học thực nghiệm.” Bốn năm sau, Peter Naur, nhà lập trình phần mềm tiên phong người Đan Mạch cho rằng datalogy – “khoa học về dữ liệu và các quy trình dữ liệu” là một giải pháp thay thế cho khoa học máy tính. Sau đó, ông sử dụng thuật ngữ data science (khoa học dữ liệu) trong cuốn sách Concise Survey of Computer Methods (1974) của mình, mô tả đây là “khoa học xử lý dữ liệu” – mặc dù đó không phải là về phân tích trong ngữ cảnh của khoa học máy tính.
Năm 1996, Hiệp hội phân loại quốc tế (International Federation of Classification Societies) đã đưa khoa học dữ liệu vào tên của hội nghị mà họ tổ chức năm đó. Trong một bài diễn thuyết tại sự kiện, chuyên gia thống kê Nhật Bản Chikio Hayashi cho biết khoa học dữ liệu gồm ba giai đoạn: “thiết kế dữ liệu, thu thập dữ liệu và phân tích dựa trên dữ liệu.” Một năm sau, C. F. Jeff Wu, giáo sư đại học ở Hoa Kỳ gốc Đài Loan đề xuất rằng statistics (thống kê) nên được đổi tên thành khoa học dữ liệu và các nhà thống kê sẽ được gọi là nhà khoa học dữ liệu.
Nhà khoa học máy tính người Mỹ William S. Cleveland đã phác thảo khoa học dữ liệu là một chuyên ngành phân tích đầy đủ trong một báo có tiêu đề “Data Science: An Action Plan for Expanding the Technical Areas of Statistics”, xuất bản năm 2001 trên Tạp chí Thống kê Quốc tế. Hai tạp chí nghiên cứu tập trung vào khoa học dữ liệu đã được ra mắt trong hai năm tới.
DJ Patil và Jeff Hammerbacher là những người có công đầu tiên trong việc sử dụng chức danh data scientist (nhà khoa học dữ liệu) làm chức danh chuyên nghiệp, họ quyết định áp dụng nó vào năm 2008 khi làm việc tại LinkedIn và Facebook. Đến năm 2012, bài viết trên Harvard Business Review của Patil và học giả người Mỹ Thomas Davenport đã gọi nhà khoa học dữ liệu là “công việc quyến rũ nhất thế kỷ 21”. Kể từ đó, khoa học dữ liệu tiếp tục phát triển vượt bậc, một phần do sự thúc đẩy bởi việc tăng cường sử dụng AI và học máy trong các tổ chức.
14. Tương lai của khoa học dữ liệu
Khi mà khoa học dữ liệu ngày càng trở nên phổ biến hơn trong các tổ chức, các nhà khoa học dữ liệu công dân được kỳ vọng sẽ đóng một vai trò lớn hơn trong quá trình phân tích. Trong báo cáo Magic Quadrant năm 2020 về khoa học dữ liệu và nền tảng học máy, Gartner cho biết nhu cầu hỗ trợ một nhóm rộng rãi người dùng khoa học dữ liệu “ngày càng trở thành quy chuẩn.” Kết quả là việc sử dụng học máy tự động ngày càng tăng, bao gồm cả việc các nhà khoa học dữ liệu lành nghề tìm cách sắp xếp và thúc đẩy công việc của họ.
Gartner cũng trích dẫn sự xuất hiện của machine learning operations (MLOps), một khái niệm điều chỉnh thực tiễn DevOps từ phát triển phần mềm nhằm nỗ lực quản lý tốt hơn việc phát triển, triển khai và bảo trì các mô hình học máy. Các phương pháp và công cụ MLOps giúp tạo ra các quy trình làm việc chuẩn hóa để lập kế hoạch, xây dựng và đưa các mô hình vào sản xuất hiệu quả hơn.
Những xu thế khác sẽ ảnh hưởng đến công việc của các nhà khoa học dữ liệu trong tương lai bao gồm sự thúc đẩy ngày càng tăng đối với AI, cung cấp thông tin để giúp mọi người hiểu cách AI và các mô hình học máy hoạt động, và mức độ tin tưởng vào những phát hiện của họ trong việc đưa ra quyết định và trọng tâm liên quan đến các nguyên tắc AI có trách nhiệm được thiết kế để đảm bảo công nghệ AI công bằng, không thiên vị và minh bạch.
>>> Nếu bạn đang có nhu cầu học lập trình trực tuyến, tìm hiểu ngay tại đây:
 >>> Xem thêm các chủ đề hữu ích:
>>> Xem thêm các chủ đề hữu ích:
- Tất cả những điều bạn cần biết về khóa học lập trình tại FUNiX FPT
- 5 Điểm đáng chú ý tại khóa học lập trình trực tuyến FPT – FUNiX
- Từ A-Z chương trình học FUNiX – Mô hình đào tạo lập trình trực tuyến số 1 Việt Nam
- Lý do phổ biến khiến học viên nước ngoài chọn FUNiX
- Lưu ý để học blockchain trực tuyến hiệu quả cao tại FUNiX
- Lý do nữ giới nên chọn FUNiX để học chuyển nghề IT
- FUNiX trở thành đối tác của Liên minh Blockchain Việt Nam
- 3 lý do bạn trẻ nên học blockchain trực tuyến ở FUNiX
Nguyễn Hải Nam
Dịch từ bài: What is data science? The ultimate guide
Bài liên quan
Đào tạo AI nội bộ cho doanh nghiệp: Bắt đầu từ kỹ năng nào?
Mô hình FUNiX Way trong đào tạo nhân sự 4.0: Khác gì cách học truyền thống?
App Inventor và Robotics: Tự thiết kế ứng dụng điều khiển Robot trên điện thoại
Lộ trình học lập trình Robot cho học sinh từ lớp 6 đến lớp 12
Robotics là gì? Tại sao học sinh cần học Robotics từ sớm trong năm 2026?
Review khóa học Fintech FUNiX: Đào tạo thực chiến 7 tháng cho người mới
Ứng dụng GenAI trong phân tích dữ liệu và vận hành Fintech
Quản trị rủi ro Fintech: Cách AI bảo vệ dòng tiền và ngăn chặn gian lận
Đăng ký nhận bản tin




Bình luận (0
)