Sắp xếp dữ liệu AI: Bí quyết cho việc học máy thành công
Việc sắp xếp dữ liệu AI là bí quyết giúp học máy (machine learning) thành công. Nó đóng một vai trò quan trọng trong việc chuẩn bị dữ liệu để phân tích, đảm bảo tính chính xác, đầy đủ và phù hợp của dữ liệu.
- Khóa học phát triển kỹ năng AI cho sinh viên: chìa khóa mở cánh cửa tương lai số
- Học AI giúp sinh viên dễ xin việc tăng lợi thế cạnh tranh trong thị trường lao động mới
- Học AI cơ bản cho học sinh - Khởi đầu sớm, lợi thế lớn
- Dạy AI cho học sinh trường chuyên THPT – Học hiểu nhanh, ôn thi hiệu quả
- Chương trình AI cho sinh viên đại học - Gợi ý từ FUNiX để bắt đầu đúng hướng
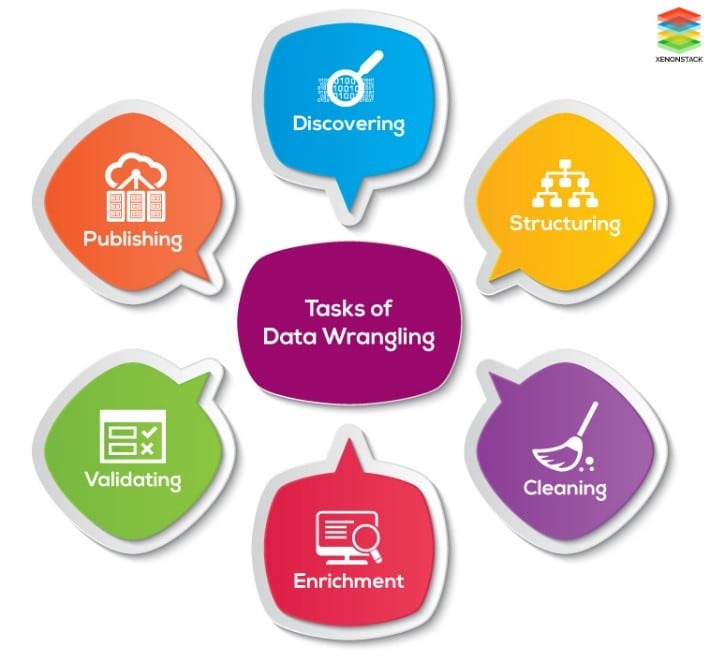
Việc sắp xếp dữ liệu AI (AI Data Wrangling) là bí quyết giúp học máy (machine learning) thành công. Nó đóng một vai trò quan trọng trong việc chuẩn bị dữ liệu để phân tích, đảm bảo tính chính xác, đầy đủ và phù hợp của dữ liệu. Bằng cách giải quyết các vấn đề về chất lượng dữ liệu, tích hợp các nguồn dữ liệu khác nhau, chuyển đổi dữ liệu thành các định dạng phù hợp và làm phong phú các tập dữ liệu bằng thông tin bên ngoài, việc sắp xếp dữ liệu cho phép phát triển các mô hình học máy chính xác và đáng tin cậy.
Vai trò của việc sắp xếp dữ liệu AI đối với học máy
Trong thế giới trí tuệ nhân tạo (AI), dữ liệu là nguồn sống cung cấp năng lượng cho các thuật toán và mô hình hỗ trợ máy học. Nếu không có dữ liệu chất lượng cao, được tổ chức tốt, ngay cả các hệ thống AI tiên tiến nhất cũng sẽ gặp khó khăn trong việc đưa ra dự đoán chính xác hoặc cung cấp những hiểu biết sâu sắc có ý nghĩa. Đây là lúc việc sắp xếp dữ liệu AI phát huy tác dụng – quá trình làm sạch, chuyển đổi và chuẩn bị dữ liệu để phân tích.
Xử lý dữ liệu
Sắp xếp dữ liệu AI là một bước quan trọng trong quy trình học máy và tầm quan trọng của nó là không thể phủ nhận. Nó bao gồm một loạt nhiệm vụ, bao gồm làm sạch dữ liệu, tích hợp dữ liệu, chuyển đổi dữ liệu và làm giàu dữ liệu. Những nhiệm vụ này là cần thiết để đảm bảo rằng dữ liệu được sử dụng cho các mô hình học máy đào tạo là chính xác, đầy đủ và phù hợp.
Một trong những thách thức chính trong việc sắp xếp dữ liệu AI là xử lý dữ liệu lộn xộn và không có cấu trúc. Dữ liệu trong thế giới thực thường không đầy đủ, không nhất quán và có nhiều lỗi. Ví dụ: trong tập dữ liệu hồ sơ khách hàng, một số mục có thể thiếu giá trị, trong khi những mục khác có thể chứa thông tin trùng lặp hoặc không chính xác. Kỹ thuật sắp xếp dữ liệu giúp giải quyết những vấn đề này bằng cách xác định và giải quyết các vấn đề về chất lượng dữ liệu.
Tích hợp dữ liệu
Tích hợp dữ liệu là một khía cạnh quan trọng khác của việc sắp xếp dữ liệu AI. Trong nhiều trường hợp, dữ liệu được sử dụng cho machine learning đến từ nhiều nguồn, chẳng hạn như cơ sở dữ liệu, bảng tính và API. Việc tích hợp các nguồn dữ liệu khác nhau này thành một định dạng thống nhất là điều cần thiết để phân tích hiệu quả. Các công cụ và kỹ thuật sắp xếp dữ liệu cho phép các nhà khoa học dữ liệu hợp nhất, nối và kết hợp các bộ dữ liệu, đảm bảo rằng tất cả thông tin liên quan đều có sẵn để phân tích.
Thay đổi định dạng
Sau khi dữ liệu được làm sạch và tích hợp, nó thường cần được chuyển đổi sang định dạng phù hợp cho các thuật toán học máy. Điều này có thể liên quan đến việc chuyển đổi các biến phân loại thành biểu diễn số, chia tỷ lệ hoặc chuẩn hóa các tính năng số hoặc tạo các tính năng dẫn xuất mới. Chuyển đổi dữ liệu là một bước quan trọng trong việc xử lý dữ liệu AI, vì nó giúp tối ưu hóa dữ liệu cho các yêu cầu cụ thể của mô hình học máy đang được sử dụng.
Làm giàu dữ liệu
Làm giàu dữ liệu là một khía cạnh quan trọng khác của việc sắp xếp dữ liệu AI. Đôi khi, dữ liệu có sẵn có thể không chứa tất cả thông tin cần thiết để đưa ra dự đoán chính xác hoặc rút ra những hiểu biết có ý nghĩa. Trong những trường hợp như vậy, các nhà khoa học dữ liệu có thể tận dụng các nguồn dữ liệu bên ngoài để bổ sung cho tập dữ liệu hiện có. Ví dụ: trong kịch bản bảo trì dự đoán, dữ liệu cảm biến lịch sử có thể được bổ sung thêm dữ liệu thời tiết để cải thiện độ chính xác của các dự đoán lỗi. Kỹ thuật sắp xếp dữ liệu cho phép tích hợp liền mạch dữ liệu bên ngoài, nâng cao chất lượng và tính hữu ích của tập dữ liệu.
Hiệu quả của sắp xếp dữ liệu AI
Lợi ích của việc sắp xếp dữ liệu AI hiệu quả là rất đa dạng. Đầu tiên và quan trọng nhất, nó cải thiện độ chính xác và độ tin cậy của các mô hình học máy. Bằng cách đảm bảo rằng dữ liệu được sử dụng để đào tạo có chất lượng cao và phù hợp, việc sắp xếp dữ liệu sẽ giảm nguy cơ dự đoán sai lệch hoặc sai sót. Ngoài ra, việc sắp xếp dữ liệu giúp tiết kiệm thời gian và tài nguyên bằng cách tự động hóa các tác vụ chuyển đổi và làm sạch dữ liệu lặp đi lặp lại. Điều này cho phép các nhà khoa học dữ liệu tập trung vào phân tích cấp độ cao hơn và phát triển mô hình, đẩy nhanh quá trình học máy.
Kết luận
Tóm lại, việc sắp xếp dữ liệu AI là bí quyết giúp học máy thành công. Nó đóng một vai trò quan trọng trong việc chuẩn bị dữ liệu để phân tích, đảm bảo tính chính xác, đầy đủ và phù hợp của dữ liệu. Bằng cách giải quyết các vấn đề về chất lượng dữ liệu, tích hợp các nguồn dữ liệu khác nhau, chuyển đổi dữ liệu thành các định dạng phù hợp và làm phong phú các tập dữ liệu bằng thông tin bên ngoài, việc sắp xếp dữ liệu cho phép phát triển các mô hình học máy chính xác và đáng tin cậy. Tầm quan trọng của nó không thể bị phóng đại trong kỷ nguyên AI, nơi dữ liệu là chìa khóa để khai thác toàn bộ tiềm năng của các hệ thống thông minh.
Quỳnh Anh (dịch từ Ts2.space: https://ts2.space/en/ai-data-wrangling-the-secret-sauce-for-machine-learning-success/)
![]()
Tin liên quan:
- So sánh Công nghệ Flashblade với các giải pháp lưu trữ truyền thống
- Tận dụng Predictive Analytics (Phân tích Dự đoán) để cải thiện kết quả học tập
- Khám phá Software-Defined Radio (vô tuyến định nghĩa bằng phần mềm – SDR)
- Mã hóa Homomorphic: Khai phá tiềm năng bảo mật và quyền riêng tư
- Public Key Infrastructure trong việc tăng cường bảo mật công nghệ Blockchain
- Chàng công nhân trở thành lập trình viên sau khóa học online ở tuổi 24
- Áp dụng AI trong quản lý chiến lược để nâng cao khả năng ra quyết định
- Tác động của AI trong quản lý vấn đề CNTT
- Học tập thích ứng bằng AI: Công cụ tối ưu cho việc giảng dạy
- Cải thiện quy trình làm việc với các giải pháp xử lý tài liệu thông minh
- AI ASIC trong thúc đẩy đổi mới và hiệu quả trong trí tuệ nhân tạo
Bài liên quan

AI Agent Operator là gì? Năng lực mới cho người làm nghiệp vụ

Vibe coding có cần biết lập trình không?

Tự động hóa công việc với AI: chọn tác vụ nào để bắt đầu?
Nghề lập trình viên thay đổi thế nào trong kỷ nguyên AI?
Đào tạo AI nội bộ cho doanh nghiệp: Bắt đầu từ kỹ năng nào?
Mô hình FUNiX Way trong đào tạo nhân sự 4.0: Khác gì cách học truyền thống?
App Inventor và Robotics: Tự thiết kế ứng dụng điều khiển Robot trên điện thoại
Lộ trình học lập trình Robot cho học sinh từ lớp 6 đến lớp 12
Đăng ký nhận bản tin




Bình luận (0
)